 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Autoencoders++: Fast and Accurate Cycle-Aware Dimensionality Reduction
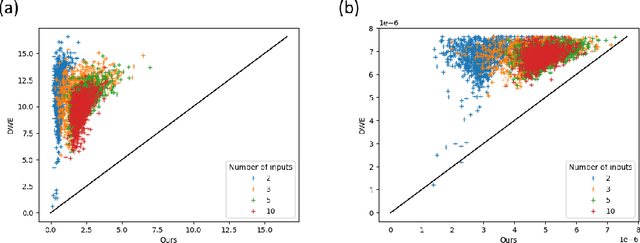
Feb 27, 2025This paper presents a novel topology-aware dimensionality reduction approach aiming at accurately visualizing the cyclic patterns present in high dimensional data. To that end, we build on the Topological Autoencoders (TopoAE) formulation. First, we provide a novel theoretical analysis of its associated loss and show that a zero loss indeed induces identical persistence pairs (in high and low dimensions) for the $0$-dimensional persistent homology (PH$^0$) of the Rips filtration. We also provide a counter example showing that this property no longer holds for a naive extension of TopoAE to PH$^d$ for $d\ge 1$. Based on this observation, we introduce a novel generalization of TopoAE to $1$-dimensional persistent homology (PH$^1$), called TopoAE++, for the accurate generation of cycle-aware planar embeddings, addressing the above failure case. This generalization is based on the notion of cascade distortion, a new penalty term favoring an isometric embedding of the $2$-chains filling persistent $1$-cycles, hence resulting in more faithful geometrical reconstructions of the $1$-cycles in the plane. We further introduce a novel, fast algorithm for the exact computation of PH for Rips filtrations in the plane, yielding improved runtimes over previously documented topology-aware methods. Our method also achieves a better balance between the topological accuracy, as measured by the Wasserstein distance, and the visual preservation of the cycles in low dimensions. Our C++ implementation is available at https://github.com/MClemot/TopologicalAutoencodersPlusPlus.
Eagle: Large-Scale Learning of Turbulent Fluid Dynamics with Mesh Transformers
Feb 16, 2023Estimating fluid dynamics is classically done through the simulation and integration of numerical models solving the Navier-Stokes equations, which is computationally complex and time-consuming even on high-end hardware. This is a notoriously hard problem to solve, which has recently been addressed with machine learning, in particular graph neural networks (GNN) and variants trained and evaluated on datasets of static objects in static scenes with fixed geometry. We attempt to go beyond existing work in complexity and introduce a new model, method and benchmark. We propose EAGLE, a large-scale dataset of 1.1 million 2D meshes resulting from simulations of unsteady fluid dynamics caused by a moving flow source interacting with nonlinear scene structure, comprised of 600 different scenes of three different types. To perform future forecasting of pressure and velocity on the challenging EAGLE dataset, we introduce a new mesh transformer. It leverages node clustering, graph pooling and global attention to learn long-range dependencies between spatially distant data points without needing a large number of iterations, as existing GNN methods do. We show that our transformer outperforms state-of-the-art performance on, both, existing synthetic and real datasets and on EAGLE. Finally, we highlight that our approach learns to attend to airflow, integrating complex information in a single iteration.
* Published as a conference paper at ICLR 2023
Example-Based Sampling with Diffusion Models
Feb 10, 2023



Much effort has been put into developing samplers with specific properties, such as producing blue noise, low-discrepancy, lattice or Poisson disk samples. These samplers can be slow if they rely on optimization processes, may rely on a wide range of numerical methods, are not always differentiable. The success of recent diffusion models for image generation suggests that these models could be appropriate for learning how to generate point sets from examples. However, their convolutional nature makes these methods impractical for dealing with scattered data such as point sets. We propose a generic way to produce 2-d point sets imitating existing samplers from observed point sets using a diffusion model. We address the problem of convolutional layers by leveraging neighborhood information from an optimal transport matching to a uniform grid, that allows us to benefit from fast convolutions on grids, and to support the example-based learning of non-uniform sampling patterns. We demonstrate how the differentiability of our approach can be used to optimize point sets to enforce properties.
Lightweight integration of 3D features to improve 2D image segmentation
Dec 16, 2022Scene understanding is a major challenge of today's computer vision. Center to this task is image segmentation, since scenes are often provided as a set of pictures. Nowadays, many such datasets also provide 3D geometry information given as a 3D point cloud acquired by a laser scanner or a depth camera. To exploit this geometric information, many current approaches rely on both a 2D loss and 3D loss, requiring not only 2D per pixel labels but also 3D per point labels. However obtaining a 3D groundtruth is challenging, time-consuming and error-prone. In this paper, we show that image segmentation can benefit from 3D geometric information without requiring any 3D groundtruth, by training the geometric feature extraction with a 2D segmentation loss in an end-to-end fashion. Our method starts by extracting a map of 3D features directly from the point cloud by using a lightweight and simple 3D encoder neural network. The 3D feature map is then used as an additional input to a classical image segmentation network. During training, the 3D features extraction is optimized for the segmentation task by back-propagation through the entire pipeline. Our method exhibits state-of-the-art performance with much lighter input dataset requirements, since no 3D groundtruth is required.
Dynamic Scene Novel View Synthesis via Deferred Spatio-temporal Consistency
Sep 02, 2021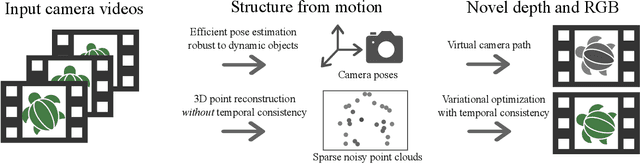


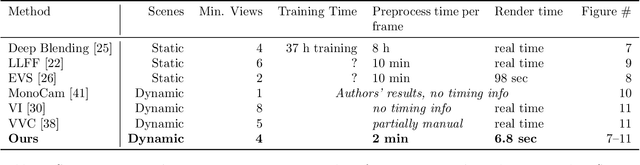
Structure from motion (SfM) enables us to reconstruct a scene via casual capture from cameras at different viewpoints, and novel view synthesis (NVS) allows us to render a captured scene from a new viewpoint. Both are hard with casual capture and dynamic scenes: SfM produces noisy and spatio-temporally sparse reconstructed point clouds, resulting in NVS with spatio-temporally inconsistent effects. We consider SfM and NVS parts together to ease the challenge. First, for SfM, we recover stable camera poses, then we defer the requirement for temporally-consistent points across the scene and reconstruct only a sparse point cloud per timestep that is noisy in space-time. Second, for NVS, we present a variational diffusion formulation on depths and colors that lets us robustly cope with the noise by enforcing spatio-temporal consistency via per-pixel reprojection weights derived from the input views. Together, this deferred approach generates novel views for dynamic scenes without requiring challenging spatio-temporally consistent reconstructions nor training complex models on large datasets. We demonstrate our algorithm on real-world dynamic scenes against classic and more recent learning-based baseline approaches.
Learning to Generate Wasserstein Barycenters
Feb 24, 2021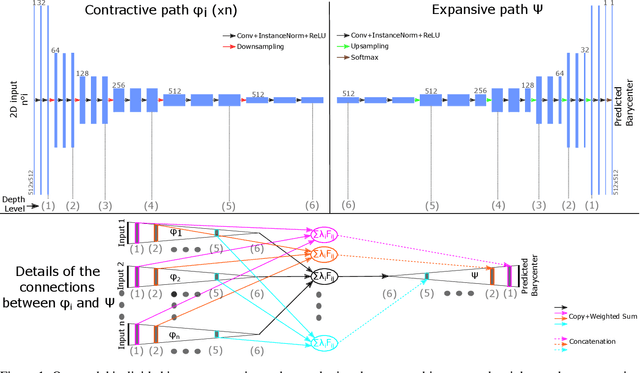

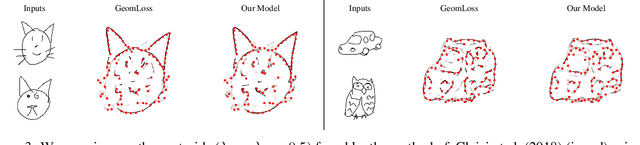
Optimal transport is a notoriously difficult problem to solve numerically, with current approaches often remaining intractable for very large scale applications such as those encountered in machine learning. Wasserstein barycenters -- the problem of finding measures in-between given input measures in the optimal transport sense -- is even more computationally demanding as it requires to solve an optimization problem involving optimal transport distances. By training a deep convolutional neural network, we improve by a factor of 60 the computational speed of Wasserstein barycenters over the fastest state-of-the-art approach on the GPU, resulting in milliseconds computational times on $512\times512$ regular grids. We show that our network, trained on Wasserstein barycenters of pairs of measures, generalizes well to the problem of finding Wasserstein barycenters of more than two measures. We demonstrate the efficiency of our approach for computing barycenters of sketches and transferring colors between multiple images.