 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning Black-Box Population-Based Optimizers
Mar 05, 2021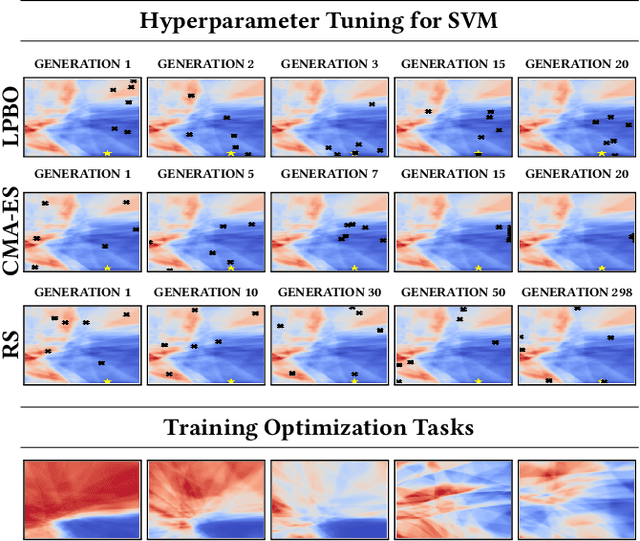
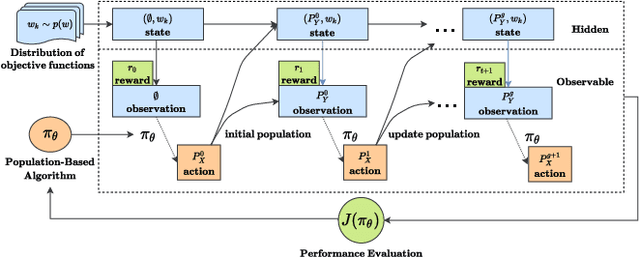
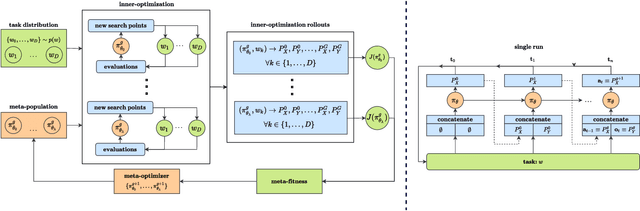

The no free lunch theorem states that no model is better suited to every problem. A question that arises from this is how to design methods that propose optimizers tailored to specific problems achieving state-of-the-art performance. This paper addresses this issue by proposing the use of meta-learning to infer population-based black-box optimizers that can automatically adapt to specific classes of problems. We suggest a general modeling of population-based algorithms that result in Learning-to-Optimize POMDP (LTO-POMDP), a meta-learning framework based on a specific partially observable Markov decision process (POMDP). From that framework's formulation, we propose to parameterize the algorithm using deep recurrent neural networks and use a meta-loss function based on stochastic algorithms' performance to train efficient data-driven optimizers over several related optimization tasks. The learned optimizers' performance based on this implementation is assessed on various black-box optimization tasks and hyperparameter tuning of machine learning models. Our results revealed that the meta-loss function encourages a learned algorithm to alter its search behavior so that it can easily fit into a new context. Thus, it allows better generalization and higher sample efficiency than state-of-the-art generic optimization algorithms, such as the Covariance matrix adaptation evolution strategy (CMA-ES).
A Novel Unsupervised Post-Processing Calibration Method for DNNS with Robustness to Domain Shift
Nov 25, 2019
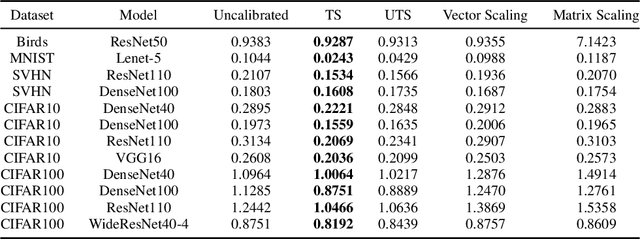
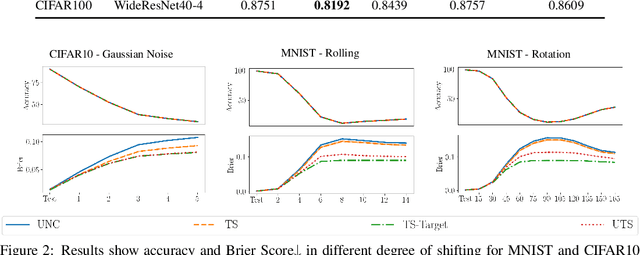
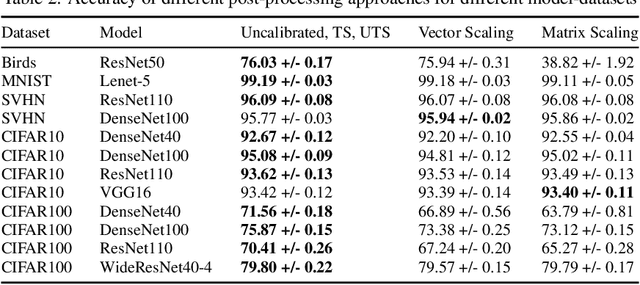
The uncertainty estimation is critical in real-world decision making applications, especially when distributional shift between the training and test data are prevalent. Many calibration methods in the literature have been proposed to improve the predictive uncertainty of DNNs which are generally not well-calibrated. However, none of them is specifically designed to work properly under domain shift condition. In this paper, we propose Unsupervised Temperature Scaling (UTS) as a robust calibration method to domain shift. It exploits unlabeled test samples instead of the training one to adjust the uncertainty prediction of deep models towards the test distribution. UTS utilizes a novel loss function, weighted NLL, which allows unsupervised calibration. We evaluate UTS on a wide range of model-datasets to show the possibility of calibration without labels and demonstrate the robustness of UTS compared to other methods (e.g., TS, MC-dropout, SVI, ensembles) in shifted domains.
Unsupervised Temperature Scaling: Post-Processing Unsupervised Calibration of Deep Models Decisions
May 08, 2019
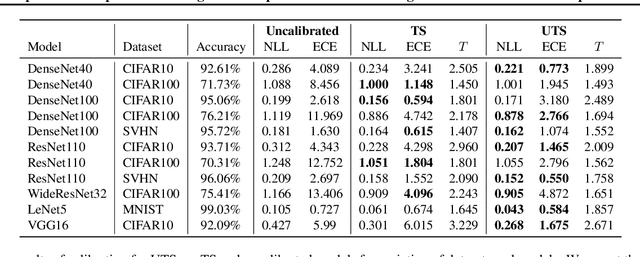
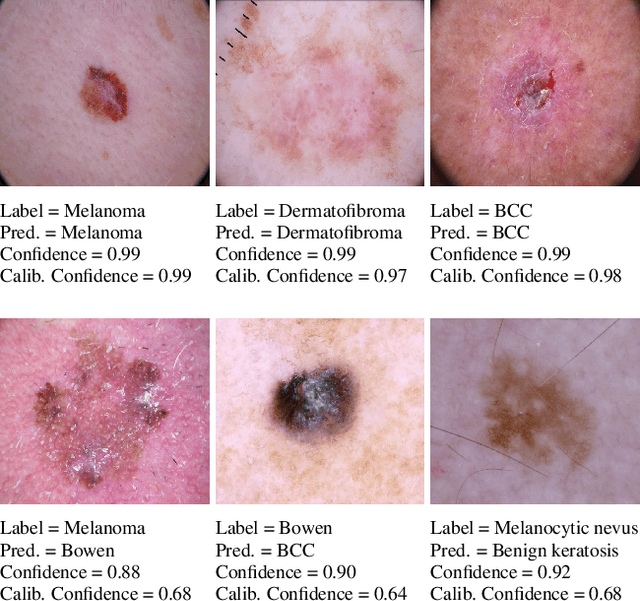

Great performances of deep learning are undeniable, with impressive results on wide range of tasks. However, the output confidence of these models is usually not well calibrated, which can be an issue for applications where confidence on the decisions is central to bring trust and reliability (e.g., autonomous driving or medical diagnosis). For models using softmax at the last layer, Temperature Scaling (TS) is a state-of-the-art calibration method, with low time and memory complexity as well as demonstrated effectiveness.TS relies on a T parameter to rescale and calibrate values of the softmax layer, using a labelled dataset to determine the value of that parameter.We are proposing an Unsupervised Temperature Scaling (UTS) approach, which does not dependent on labelled samples to calibrate the model,allowing, for example, using a part of test samples for calibrating the pre-trained model before going into inference mode. We provide theoretical justifications for UTS and assess its effectiveness on the wide range of deep models and datasets. We also demonstrate calibration results of UTS on skin lesion detection, a problem where a well-calibrated output can play an important role for accurate decision-making.
A New Loss Function for Temperature Scaling to have Better Calibrated Deep Networks
Oct 27, 2018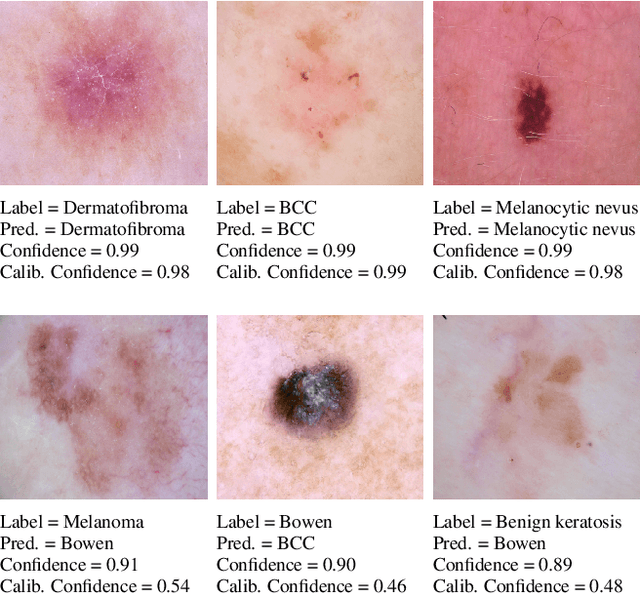
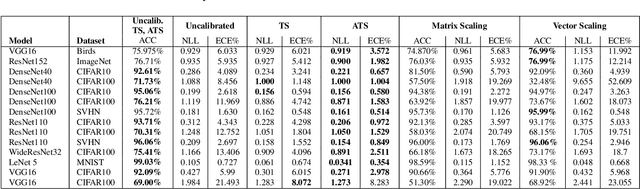
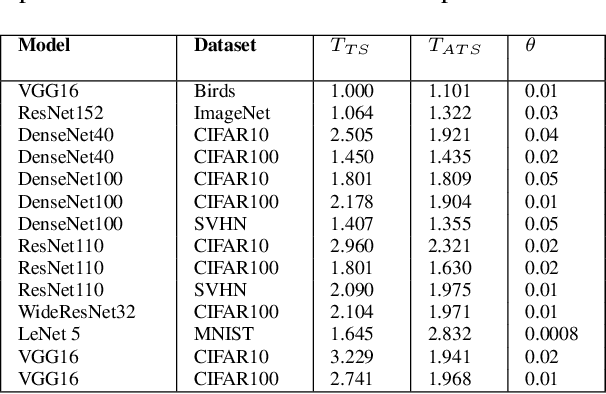
However Deep neural networks recently have achieved impressive results for different tasks, they suffer from poor uncertainty prediction. Temperature Scaling(TS) is an efficient post-processing method for calibrating DNNs toward to have more accurate uncertainty prediction. TS relies on a single parameter T which softens the logit layer of a DNN and the optimal value of it is found by minimizing on Negative Log Likelihood (NLL) loss function. In this paper, we discuss about weakness of NLL loss function, especially for DNNs with high accuracy and propose a new loss function called Attended-NLL which can improve TS calibration ability significantly