 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Long-Tailed Data With Noisy Labels
Aug 25, 2021
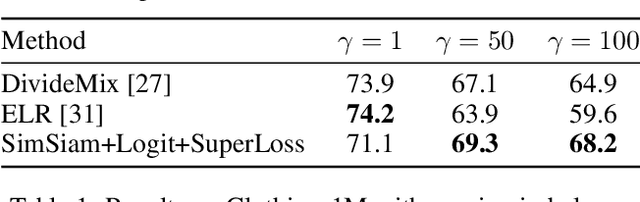
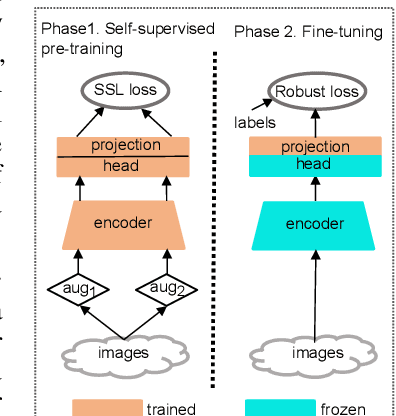

Class imbalance and noisy labels are the norm rather than the exception in many large-scale classification datasets. Nevertheless, most works in machine learning typically assume balanced and clean data. There have been some recent attempts to tackle, on one side, the problem of learning from noisy labels and, on the other side, learning from long-tailed data. Each group of methods make simplifying assumptions about the other. Due to this separation, the proposed solutions often underperform when both assumptions are violated. In this work, we present a simple two-stage approach based on recent advances in self-supervised learning to treat both challenges simultaneously. It consists of, first, task-agnostic self-supervised pre-training, followed by task-specific fine-tuning using an appropriate loss. Most significantly, we find that self-supervised learning approaches are effectively able to cope with severe class imbalance. In addition, the resulting learned representations are also remarkably robust to label noise, when fine-tuned with an imbalance- and noise-resistant loss function. We validate our claims with experiments on CIFAR-10 and CIFAR-100 augmented with synthetic imbalance and noise, as well as the large-scale inherently noisy Clothing-1M dataset.
Universal Domain Adaptation in Ordinal Regression
Jun 22, 2021
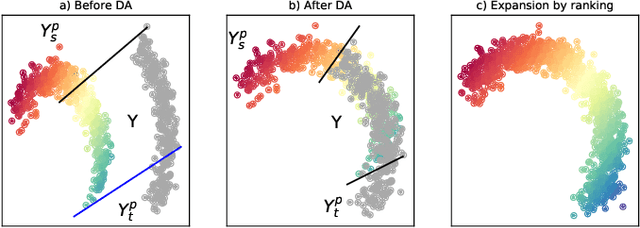
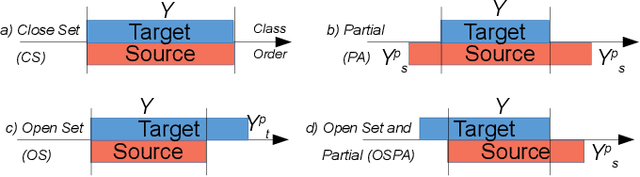
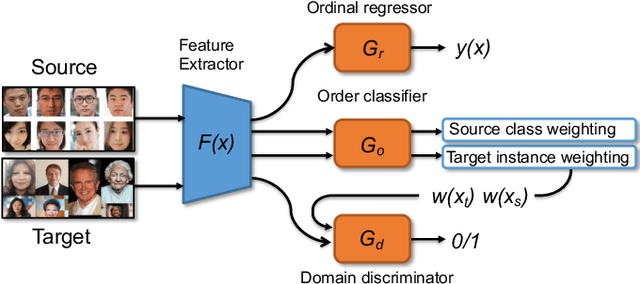
We address the problem of universal domain adaptation (UDA) in ordinal regression (OR), which attempts to solve classification problems in which labels are not independent, but follow a natural order. We show that the UDA techniques developed for classification and based on the clustering assumption, under-perform in OR settings. We propose a method that complements the OR classifier with an auxiliary task of order learning, which plays the double role of discriminating between common and private instances, and expanding class labels to the private target images via ranking. Combined with adversarial domain discrimination, our model is able to address the closed set, partial and open set configurations. We evaluate our method on three face age estimation datasets, and show that it outperforms the baseline methods.