 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Attention Learning for Depth and Ego-motion Estimation
Paper and Code
Apr 27, 2020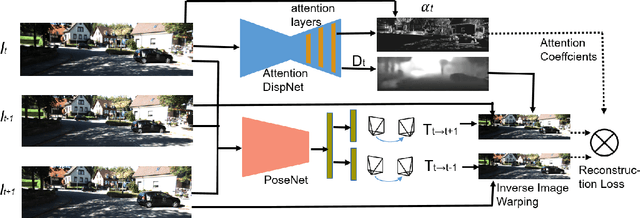
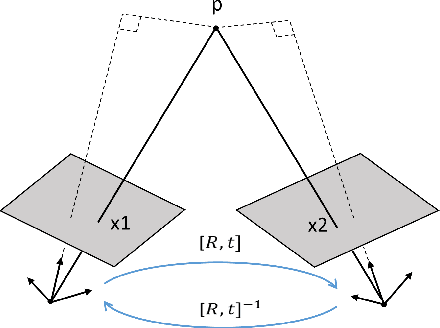
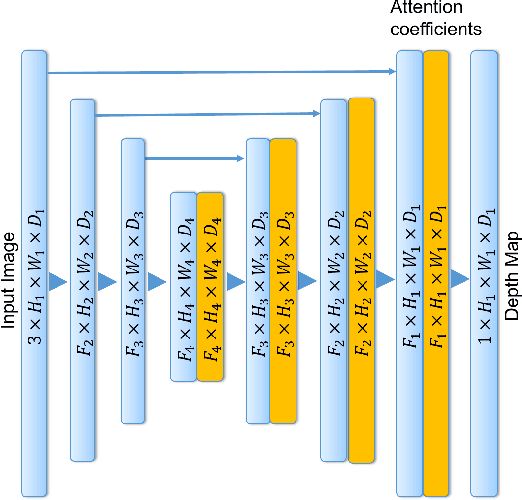

We address the problem of depth and ego-motion estimation from image sequences. Recent advances in the domain propose to train a deep learning model for both tasks using image reconstruction in a self-supervised manner. We revise the assumptions and the limitations of the current approaches and propose two improvements to boost the performance of the depth and ego-motion estimation. We first use Lie group properties to enforce the geometric consistency between images in the sequence and their reconstructions. We then propose a mechanism to pay an attention to image regions where the image reconstruction get corrupted. We show how to integrate the attention mechanism in the form of attention gates in the pipeline and use attention coefficients as a mask. We evaluate the new architecture on the KITTI datasets and compare it to the previous techniques. We show that our approach improves the state-of-the-art results for ego-motion estimation and achieve comparable results for depth estimation.