 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate and Human-Like Driving using Semantic Maps and Attention
Paper and Code
Jul 10, 2020
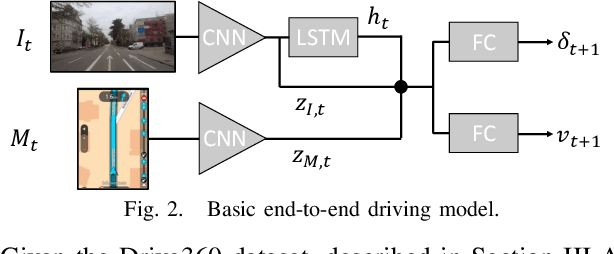
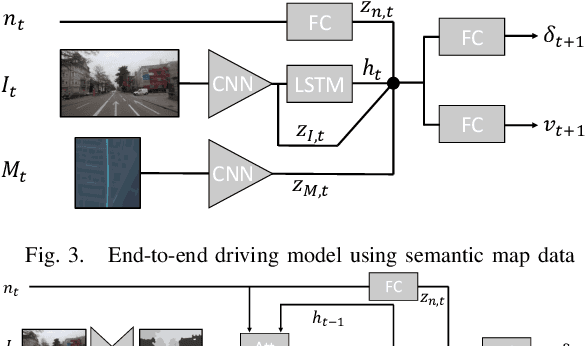
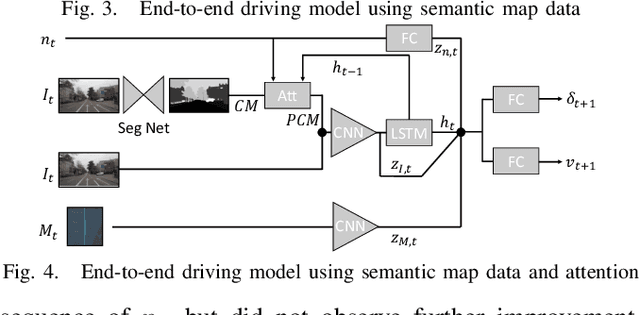
This paper investigates how end-to-end driving models can be improved to drive more accurately and human-like. To tackle the first issue we exploit semantic and visual maps from HERE Technologies and augment the existing Drive360 dataset with such. The maps are used in an attention mechanism that promotes segmentation confidence masks, thus focusing the network on semantic classes in the image that are important for the current driving situation. Human-like driving is achieved using adversarial learning, by not only minimizing the imitation loss with respect to the human driver but by further defining a discriminator, that forces the driving model to produce action sequences that are human-like. Our models are trained and evaluated on the Drive360 + HERE dataset, which features 60 hours and 3000 km of real-world driving data. Extensive experiments show that our driving models are more accurate and behave more human-like than previous methods.