 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior
Paper and Code



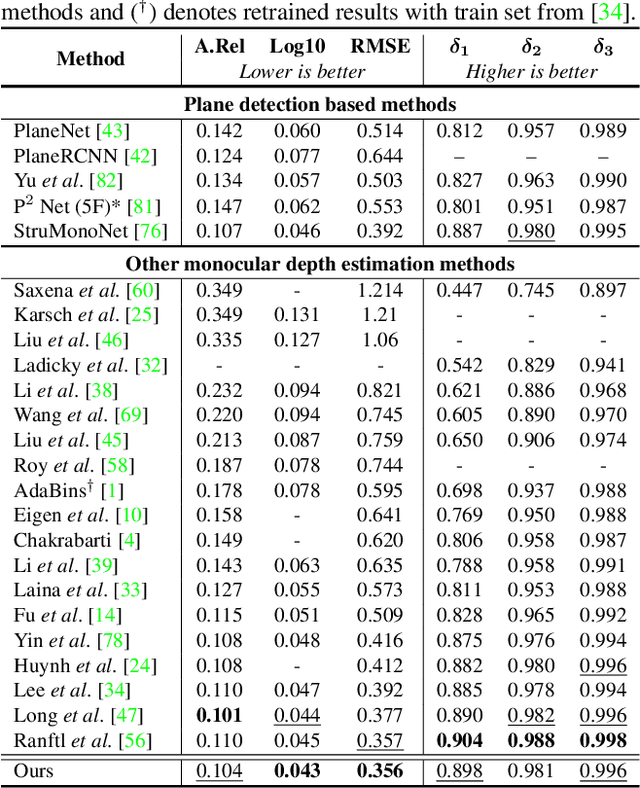
Monocular depth estimation is vital for scene understanding and downstream tasks. We focus on the supervised setup, in which ground-truth depth is available only at training time. Based on knowledge about the high regularity of real 3D scenes, we propose a method that learns to selectively leverage information from coplanar pixels to improve the predicted depth. In particular, we introduce a piecewise planarity prior which states that for each pixel, there is a seed pixel which shares the same planar 3D surface with the former. Motivated by this prior, we design a network with two heads. The first head outputs pixel-level plane coefficients, while the second one outputs a dense offset vector field that identifies the positions of seed pixels. The plane coefficients of seed pixels are then used to predict depth at each position. The resulting prediction is adaptively fused with the initial prediction from the first head via a learned confidence to account for potential deviations from precise local planarity. The entire architecture is trained end-to-end thanks to the differentiability of the proposed modules and it learns to predict regular depth maps, with sharp edges at occlusion boundaries. An extensive evaluation of our method shows that we set the new state of the art in supervised monocular depth estimation, surpassing prior methods on NYU Depth-v2 and on the Garg split of KITTI. Our method delivers depth maps that yield plausible 3D reconstructions of the input scenes. Code is available at: https://github.com/SysCV/P3Depth