 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerrain-aware Low Altitude Path Planning
May 11, 2025
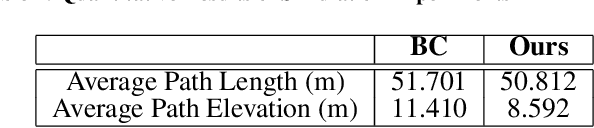


In this paper, we study the problem of generating low altitude path plans for nap-of-the-earth (NOE) flight in real time with only RGB images from onboard cameras and the vehicle pose. We propose a novel training method that combines behavior cloning and self-supervised learning that enables the learned policy to outperform the policy trained with standard behavior cloning approach on this task. Simulation studies are performed on a custom canyon terrain.
PRIMER: Perception-Aware Robust Learning-based Multiagent Trajectory Planner
Jun 14, 2024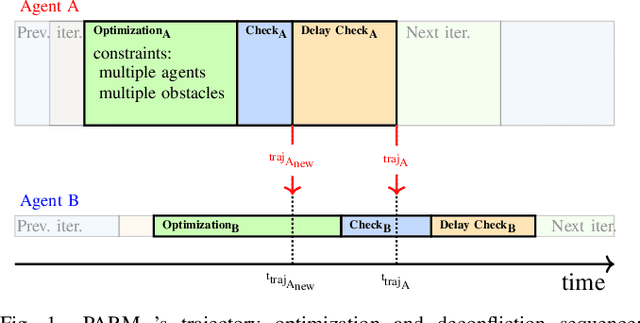
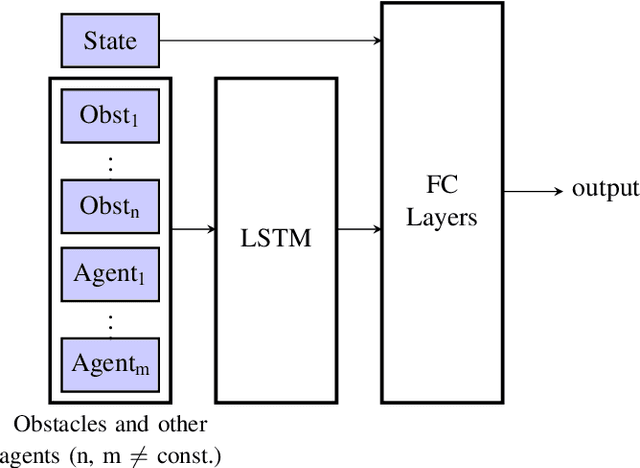
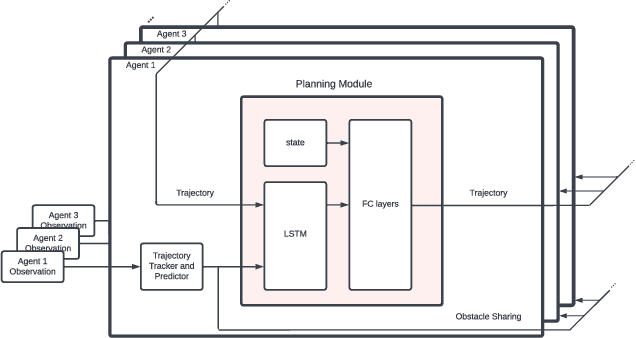

In decentralized multiagent trajectory planners, agents need to communicate and exchange their positions to generate collision-free trajectories. However, due to localization errors/uncertainties, trajectory deconfliction can fail even if trajectories are perfectly shared between agents. To address this issue, we first present PARM and PARM*, perception-aware, decentralized, asynchronous multiagent trajectory planners that enable a team of agents to navigate uncertain environments while deconflicting trajectories and avoiding obstacles using perception information. PARM* differs from PARM as it is less conservative, using more computation to find closer-to-optimal solutions. While these methods achieve state-of-the-art performance, they suffer from high computational costs as they need to solve large optimization problems onboard, making it difficult for agents to replan at high rates. To overcome this challenge, we present our second key contribution, PRIMER, a learning-based planner trained with imitation learning (IL) using PARM* as the expert demonstrator. PRIMER leverages the low computational requirements at deployment of neural networks and achieves a computation speed up to 5500 times faster than optimization-based approaches.
CGD: Constraint-Guided Diffusion Policies for UAV Trajectory Planning
May 02, 2024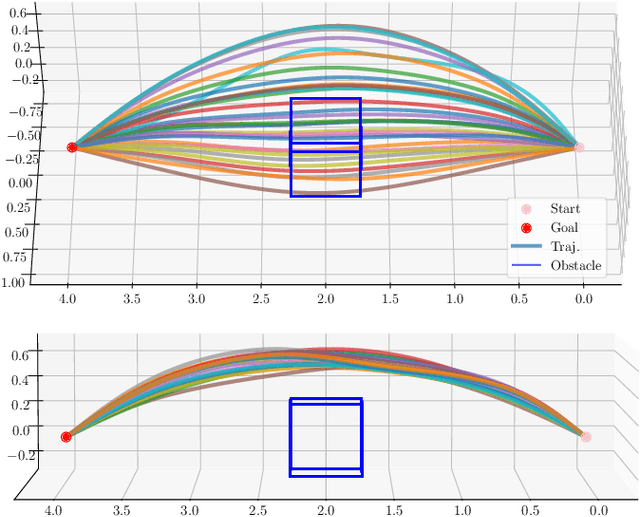
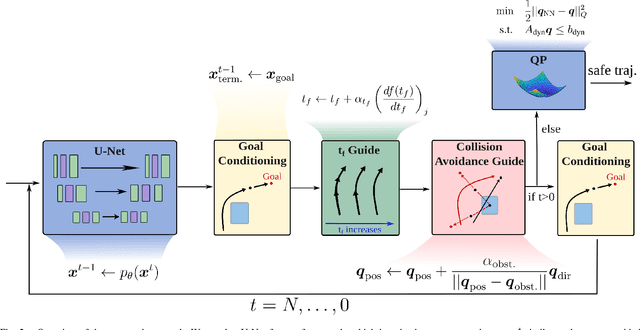
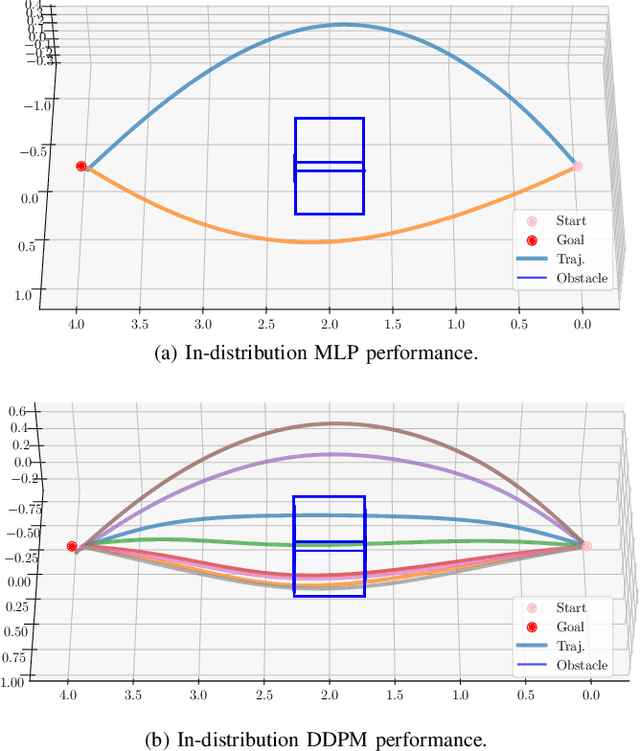
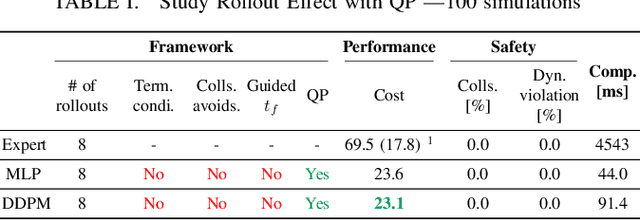
Traditional optimization-based planners, while effective, suffer from high computational costs, resulting in slow trajectory generation. A successful strategy to reduce computation time involves using Imitation Learning (IL) to develop fast neural network (NN) policies from those planners, which are treated as expert demonstrators. Although the resulting NN policies are effective at quickly generating trajectories similar to those from the expert, (1) their output does not explicitly account for dynamic feasibility, and (2) the policies do not accommodate changes in the constraints different from those used during training. To overcome these limitations, we propose Constraint-Guided Diffusion (CGD), a novel IL-based approach to trajectory planning. CGD leverages a hybrid learning/online optimization scheme that combines diffusion policies with a surrogate efficient optimization problem, enabling the generation of collision-free, dynamically feasible trajectories. The key ideas of CGD include dividing the original challenging optimization problem solved by the expert into two more manageable sub-problems: (a) efficiently finding collision-free paths, and (b) determining a dynamically-feasible time-parametrization for those paths to obtain a trajectory. Compared to conventional neural network architectures, we demonstrate through numerical evaluations significant improvements in performance and dynamic feasibility under scenarios with new constraints never encountered during training.
Tube-NeRF: Efficient Imitation Learning of Visuomotor Policies from MPC using Tube-Guided Data Augmentation and NeRFs
Nov 23, 2023



Imitation learning (IL) can train computationally-efficient sensorimotor policies from a resource-intensive Model Predictive Controller (MPC), but it often requires many samples, leading to long training times or limited robustness. To address these issues, we combine IL with a variant of robust MPC that accounts for process and sensing uncertainties, and we design a data augmentation (DA) strategy that enables efficient learning of vision-based policies. The proposed DA method, named Tube-NeRF, leverages Neural Radiance Fields (NeRFs) to generate novel synthetic images, and uses properties of the robust MPC (the tube) to select relevant views and to efficiently compute the corresponding actions. We tailor our approach to the task of localization and trajectory tracking on a multirotor, by learning a visuomotor policy that generates control actions using images from the onboard camera as only source of horizontal position. Our evaluations numerically demonstrate learning of a robust visuomotor policy with an 80-fold increase in demonstration efficiency and a 50% reduction in training time over current IL methods. Additionally, our policies successfully transfer to a real multirotor, achieving accurate localization and low tracking errors despite large disturbances, with an onboard inference time of only 1.5 ms.
PUMA: Fully Decentralized Uncertainty-aware Multiagent Trajectory Planner with Real-time Image Segmentation-based Frame Alignment
Nov 07, 2023Fully decentralized, multiagent trajectory planners enable complex tasks like search and rescue or package delivery by ensuring safe navigation in unknown environments. However, deconflicting trajectories with other agents and ensuring collision-free paths in a fully decentralized setting is complicated by dynamic elements and localization uncertainty. To this end, this paper presents (1) an uncertainty-aware multiagent trajectory planner and (2) an image segmentation-based frame alignment pipeline. The uncertainty-aware planner propagates uncertainty associated with the future motion of detected obstacles, and by incorporating this propagated uncertainty into optimization constraints, the planner effectively navigates around obstacles. Unlike conventional methods that emphasize explicit obstacle tracking, our approach integrates implicit tracking. Sharing trajectories between agents can cause potential collisions due to frame misalignment. Addressing this, we introduce a novel frame alignment pipeline that rectifies inter-agent frame misalignment. This method leverages a zero-shot image segmentation model for detecting objects in the environment and a data association framework based on geometric consistency for map alignment. Our approach accurately aligns frames with only 0.18 m and 2.7 deg of mean frame alignment error in our most challenging simulation scenario. In addition, we conducted hardware experiments and successfully achieved 0.29 m and 2.59 deg of frame alignment error. Together with the alignment framework, our planner ensures safe navigation in unknown environments and collision avoidance in decentralized settings.
REAL: Resilience and Adaptation using Large Language Models on Autonomous Aerial Robots
Nov 02, 2023


Large Language Models (LLMs) pre-trained on internet-scale datasets have shown impressive capabilities in code understanding, synthesis, and general purpose question-and-answering. Key to their performance is the substantial prior knowledge acquired during training and their ability to reason over extended sequences of symbols, often presented in natural language. In this work, we aim to harness the extensive long-term reasoning, natural language comprehension, and the available prior knowledge of LLMs for increased resilience and adaptation in autonomous mobile robots. We introduce REAL, an approach for REsilience and Adaptation using LLMs. REAL provides a strategy to employ LLMs as a part of the mission planning and control framework of an autonomous robot. The LLM employed by REAL provides (i) a source of prior knowledge to increase resilience for challenging scenarios that the system had not been explicitly designed for; (ii) a way to interpret natural-language and other log/diagnostic information available in the autonomy stack, for mission planning; (iii) a way to adapt the control inputs using minimal user-provided prior knowledge about the dynamics/kinematics of the robot. We integrate REAL in the autonomy stack of a real multirotor, querying onboard an offboard LLM at 0.1-1.0 Hz as part the robot's mission planning and control feedback loops. We demonstrate in real-world experiments the ability of the LLM to reduce the position tracking errors of a multirotor under the presence of (i) errors in the parameters of the controller and (ii) unmodeled dynamics. We also show (iii) decision making to avoid potentially dangerous scenarios (e.g., robot oscillates) that had not been explicitly accounted for in the initial prompt design.
Efficient Deep Learning of Robust Policies from MPC using Imitation and Tube-Guided Data Augmentation
Jun 01, 2023



Imitation Learning (IL) has been increasingly employed to generate computationally efficient policies from task-relevant demonstrations provided by Model Predictive Control (MPC). However, commonly employed IL methods are often data- and computationally-inefficient, as they require a large number of MPC demonstrations, resulting in long training times, and they produce policies with limited robustness to disturbances not experienced during training. In this work, we propose an IL strategy to efficiently compress a computationally expensive MPC into a Deep Neural Network (DNN) policy that is robust to previously unseen disturbances. By using a robust variant of the MPC, called Robust Tube MPC (RTMPC), and leveraging properties from the controller, we introduce a computationally-efficient Data Aggregation (DA) method that enables a significant reduction of the number of MPC demonstrations and training time required to generate a robust policy. Our approach opens the possibility of zero-shot transfer of a policy trained from a single MPC demonstration collected in a nominal domain, such as a simulation or a robot in a lab/controlled environment, to a new domain with previously-unseen bounded model errors/perturbations. Numerical and experimental evaluations performed using linear and nonlinear MPC for agile flight on a multirotor show that our method outperforms strategies commonly employed in IL (such as DAgger and DR) in terms of demonstration-efficiency, training time, and robustness to perturbations unseen during training.
Efficient Deep Learning of Robust, Adaptive Policies using Tube MPC-Guided Data Augmentation
Mar 28, 2023



The deployment of agile autonomous systems in challenging, unstructured environments requires adaptation capabilities and robustness to uncertainties. Existing robust and adaptive controllers, such as the ones based on MPC, can achieve impressive performance at the cost of heavy online onboard computations. Strategies that efficiently learn robust and onboard-deployable policies from MPC have emerged, but they still lack fundamental adaptation capabilities. In this work, we extend an existing efficient IL algorithm for robust policy learning from MPC with the ability to learn policies that adapt to challenging model/environment uncertainties. The key idea of our approach consists in modifying the IL procedure by conditioning the policy on a learned lower-dimensional model/environment representation that can be efficiently estimated online. We tailor our approach to the task of learning an adaptive position and attitude control policy to track trajectories under challenging disturbances on a multirotor. Our evaluation is performed in a high-fidelity simulation environment and shows that a high-quality adaptive policy can be obtained in about $1.3$ hours. We additionally empirically demonstrate rapid adaptation to in- and out-of-training-distribution uncertainties, achieving a $6.1$ cm average position error under a wind disturbance that corresponds to about $50\%$ of the weight of the robot and that is $36\%$ larger than the maximum wind seen during training.
Output Feedback Tube MPC-Guided Data Augmentation for Robust, Efficient Sensorimotor Policy Learning
Oct 18, 2022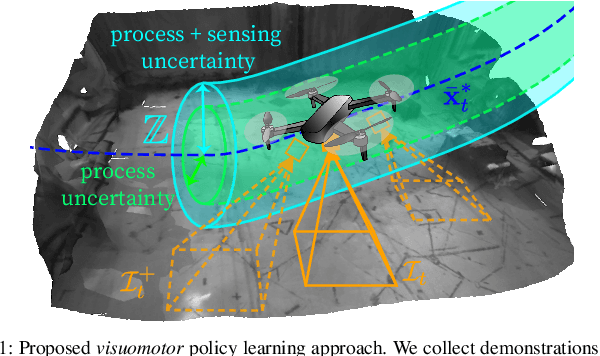

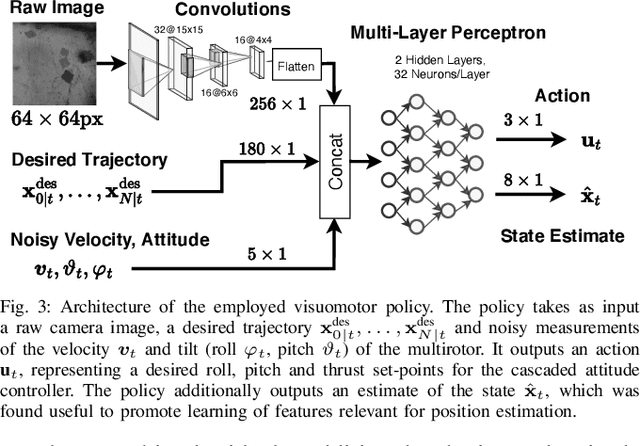
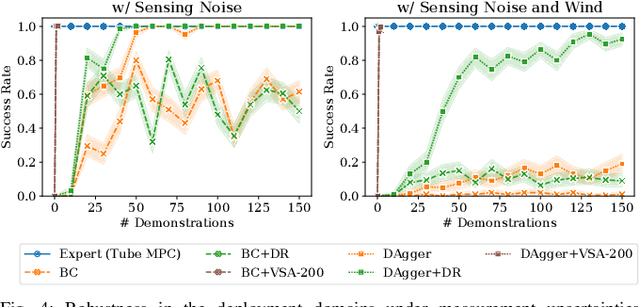
Imitation learning (IL) can generate computationally efficient sensorimotor policies from demonstrations provided by computationally expensive model-based sensing and control algorithms. However, commonly employed IL methods are often data-inefficient, requiring the collection of a large number of demonstrations and producing policies with limited robustness to uncertainties. In this work, we combine IL with an output feedback robust tube model predictive controller (RTMPC) to co-generate demonstrations and a data augmentation strategy to efficiently learn neural network-based sensorimotor policies. Thanks to the augmented data, we reduce the computation time and the number of demonstrations needed by IL, while providing robustness to sensing and process uncertainty. We tailor our approach to the task of learning a trajectory tracking visuomotor policy for an aerial robot, leveraging a 3D mesh of the environment as part of the data augmentation process. We numerically demonstrate that our method can learn a robust visuomotor policy from a single demonstration--a two-orders of magnitude improvement in demonstration efficiency compared to existing IL methods.
Robust, High-Rate Trajectory Tracking on Insect-Scale Soft-Actuated Aerial Robots with Deep-Learned Tube MPC
Sep 26, 2022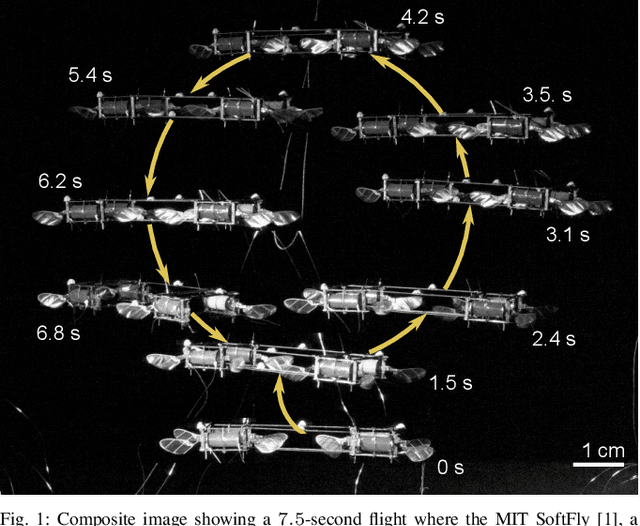
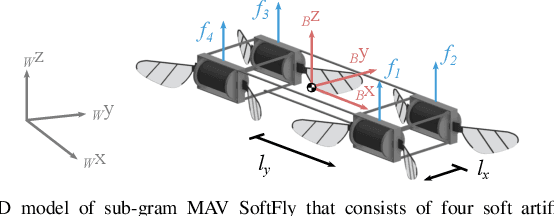
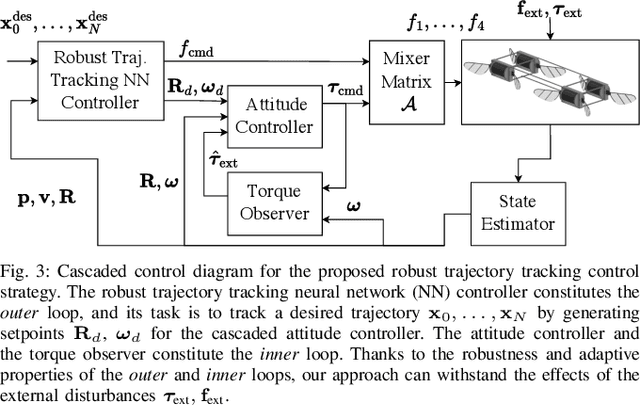
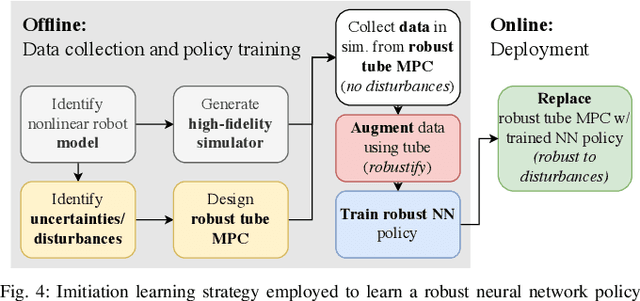
Accurate and agile trajectory tracking in sub-gram Micro Aerial Vehicles (MAVs) is challenging, as the small scale of the robot induces large model uncertainties, demanding robust feedback controllers, while the fast dynamics and computational constraints prevent the deployment of computationally expensive strategies. In this work, we present an approach for agile and computationally efficient trajectory tracking on the MIT SoftFly, a sub-gram MAV (0.7 grams). Our strategy employs a cascaded control scheme, where an adaptive attitude controller is combined with a neural network policy trained to imitate a trajectory tracking robust tube model predictive controller (RTMPC). The neural network policy is obtained using our recent work, which enables the policy to preserve the robustness of RTMPC, but at a fraction of its computational cost. We experimentally evaluate our approach, achieving position Root Mean Square Errors lower than 1.8 cm even in the more challenging maneuvers, obtaining a 60% reduction in maximum position error compared to our previous work, and demonstrating robustness to large external disturbances