 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutput Feedback Tube MPC-Guided Data Augmentation for Robust, Efficient Sensorimotor Policy Learning
Paper and Code
Oct 18, 2022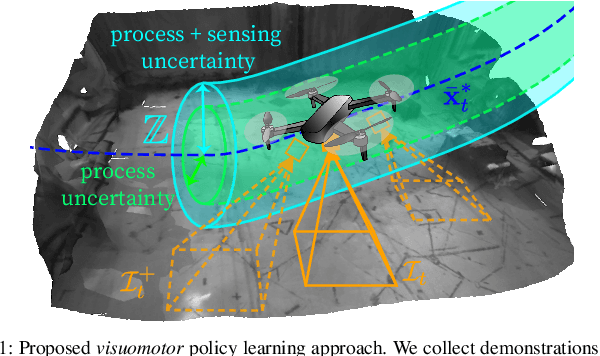

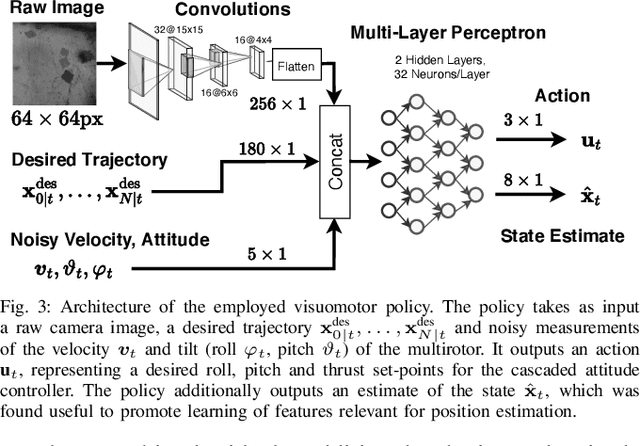
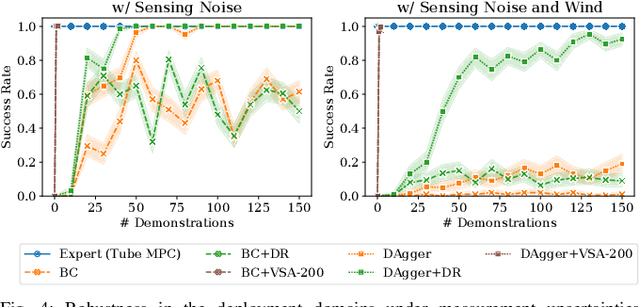
Imitation learning (IL) can generate computationally efficient sensorimotor policies from demonstrations provided by computationally expensive model-based sensing and control algorithms. However, commonly employed IL methods are often data-inefficient, requiring the collection of a large number of demonstrations and producing policies with limited robustness to uncertainties. In this work, we combine IL with an output feedback robust tube model predictive controller (RTMPC) to co-generate demonstrations and a data augmentation strategy to efficiently learn neural network-based sensorimotor policies. Thanks to the augmented data, we reduce the computation time and the number of demonstrations needed by IL, while providing robustness to sensing and process uncertainty. We tailor our approach to the task of learning a trajectory tracking visuomotor policy for an aerial robot, leveraging a 3D mesh of the environment as part of the data augmentation process. We numerically demonstrate that our method can learn a robust visuomotor policy from a single demonstration--a two-orders of magnitude improvement in demonstration efficiency compared to existing IL methods.