 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePWM: Policy Learning with Large World Models
Paper and Code
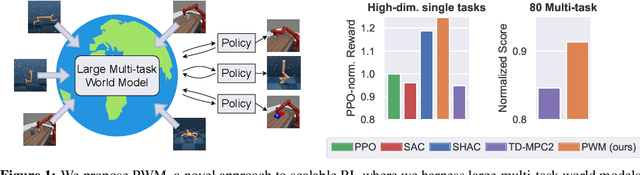


Reinforcement Learning (RL) has achieved impressive results on complex tasks but struggles in multi-task settings with different embodiments. World models offer scalability by learning a simulation of the environment, yet they often rely on inefficient gradient-free optimization methods. We introduce Policy learning with large World Models (PWM), a novel model-based RL algorithm that learns continuous control policies from large multi-task world models. By pre-training the world model on offline data and using it for first-order gradient policy learning, PWM effectively solves tasks with up to 152 action dimensions and outperforms methods using ground-truth dynamics. Additionally, PWM scales to an 80-task setting, achieving up to 27% higher rewards than existing baselines without the need for expensive online planning. Visualizations and code available at https://policy-world-model.github.io