 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGuanDan: A Large-Scale Imperfect Information Game Benchmark
Jan 31, 2026The advancement of data-driven artificial intelligence (AI), particularly machine learning, heavily depends on large-scale benchmarks. Despite remarkable progress across domains ranging from pattern recognition to intelligent decision-making in recent decades, exemplified by breakthroughs in board games, card games, and electronic sports games, there remains a pressing need for more challenging benchmarks to drive further research. To this end, this paper proposes OpenGuanDan, a novel benchmark that enables both efficient simulation of GuanDan (a popular four-player, multi-round Chinese card game) and comprehensive evaluation of both learning-based and rule-based GuanDan AI agents. OpenGuanDan poses a suite of nontrivial challenges, including imperfect information, large-scale information set and action spaces, a mixed learning objective involving cooperation and competition, long-horizon decision-making, variable action spaces, and dynamic team composition. These characteristics make it a demanding testbed for existing intelligent decision-making methods. Moreover, the independent API for each player allows human-AI interactions and supports integration with large language models. Empirically, we conduct two types of evaluations: (1) pairwise competitions among all GuanDan AI agents, and (2) human-AI matchups. Experimental results demonstrate that while current learning-based agents substantially outperform rule-based counterparts, they still fall short of achieving superhuman performance, underscoring the need for continued research in multi-agent intelligent decision-making domain. The project is publicly available at https://github.com/GameAI-NJUPT/OpenGuanDan.
Asynchronous Predictive Counterfactual Regret Minimization$^+$ Algorithm in Solving Extensive-Form Games
Mar 17, 2025



Counterfactual Regret Minimization (CFR) algorithms are widely used to compute a Nash equilibrium (NE) in two-player zero-sum imperfect-information extensive-form games (IIGs). Among them, Predictive CFR$^+$ (PCFR$^+$) is particularly powerful, achieving an exceptionally fast empirical convergence rate via the prediction in many games. However, the empirical convergence rate of PCFR$^+$ would significantly degrade if the prediction is inaccurate, leading to unstable performance on certain IIGs. To enhance the robustness of PCFR$^+$, we propose a novel variant, Asynchronous PCFR$^+$ (APCFR$^+$), which employs an adaptive asynchronization of step-sizes between the updates of implicit and explicit accumulated counterfactual regrets to mitigate the impact of the prediction inaccuracy on convergence. We present a theoretical analysis demonstrating why APCFR$^+$ can enhance the robustness. Finally, we propose a simplified version of APCFR$^+$ called Simple APCFR$^+$ (SAPCFR$^+$), which uses a fixed asynchronization of step-sizes to simplify the implementation that only needs a single-line modification of the original PCFR+. Interestingly, SAPCFR$^+$ achieves a constant-factor lower theoretical regret bound than PCFR$^+$ in the worst case. Experimental results demonstrate that (i) both APCFR$^+$ and SAPCFR$^+$ outperform PCFR$^+$ in most of the tested games, as well as (ii) SAPCFR$^+$ achieves a comparable empirical convergence rate with APCFR$^+$.
Efficient Last-iterate Convergence Algorithms in Solving Games
Aug 22, 2023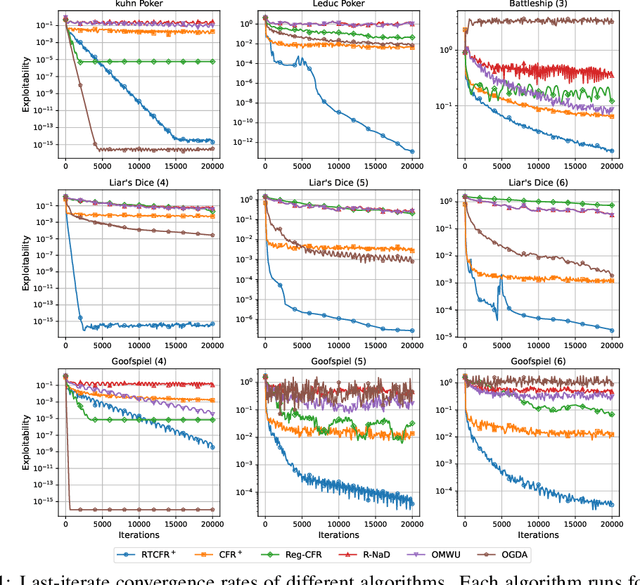
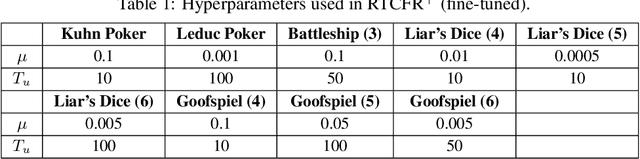
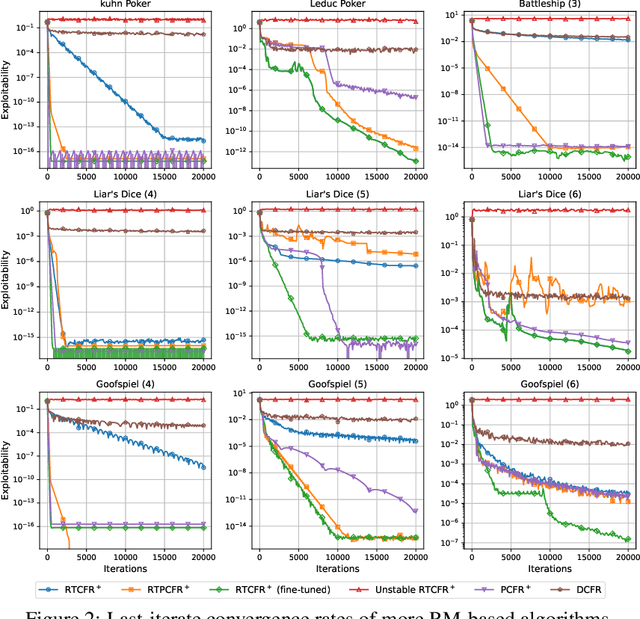
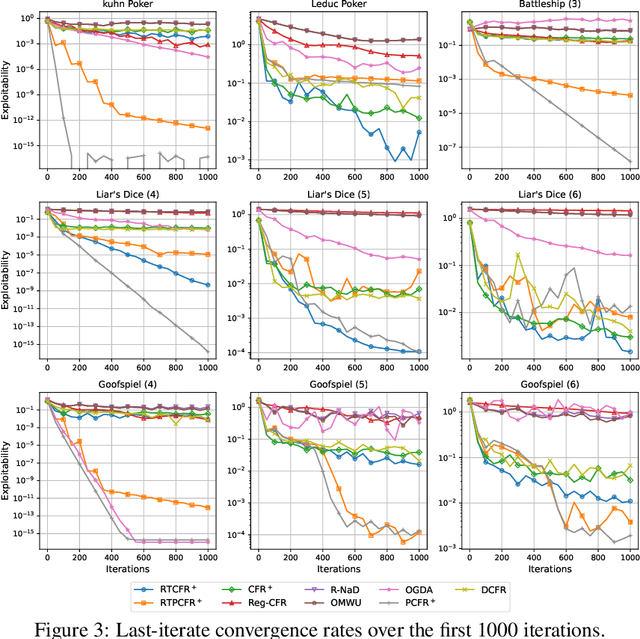
No-regret algorithms are popular for learning Nash equilibrium (NE) in two-player zero-sum normal-form games (NFGs) and extensive-form games (EFGs). Many recent works consider the last-iterate convergence no-regret algorithms. Among them, the two most famous algorithms are Optimistic Gradient Descent Ascent (OGDA) and Optimistic Multiplicative Weight Update (OMWU). However, OGDA has high per-iteration complexity. OMWU exhibits a lower per-iteration complexity but poorer empirical performance, and its convergence holds only when NE is unique. Recent works propose a Reward Transformation (RT) framework for MWU, which removes the uniqueness condition and achieves competitive performance with OMWU. Unfortunately, RT-based algorithms perform worse than OGDA under the same number of iterations, and their convergence guarantee is based on the continuous-time feedback assumption, which does not hold in most scenarios. To address these issues, we provide a closer analysis of the RT framework, which holds for both continuous and discrete-time feedback. We demonstrate that the essence of the RT framework is to transform the problem of learning NE in the original game into a series of strongly convex-concave optimization problems (SCCPs). We show that the bottleneck of RT-based algorithms is the speed of solving SCCPs. To improve the their empirical performance, we design a novel transformation method to enable the SCCPs can be solved by Regret Matching+ (RM+), a no-regret algorithm with better empirical performance, resulting in Reward Transformation RM+ (RTRM+). RTRM+ enjoys last-iterate convergence under the discrete-time feedback setting. Using the counterfactual regret decomposition framework, we propose Reward Transformation CFR+ (RTCFR+) to extend RTRM+ to EFGs. Experimental results show that our algorithms significantly outperform existing last-iterate convergence algorithms and RM+ (CFR+).