 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Load Balancing via Efficient Inverse Reinforcement Learning
Mar 22, 2023
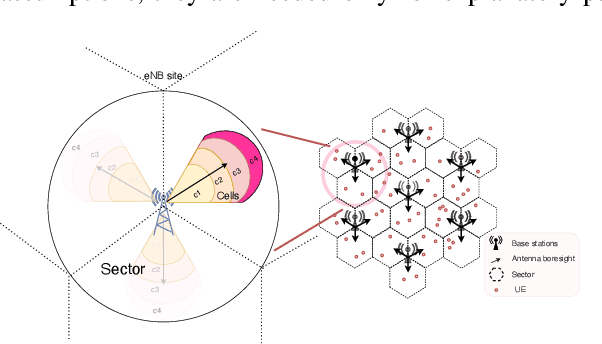
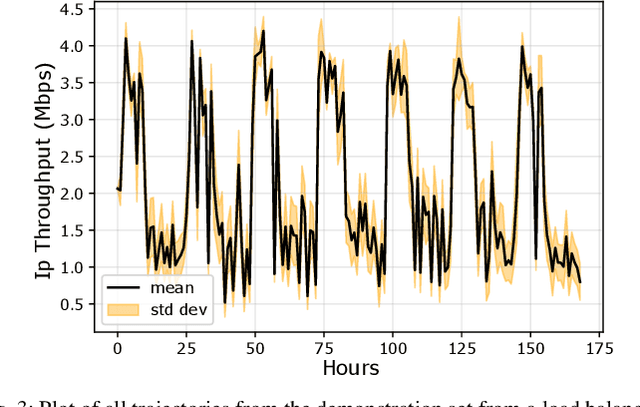
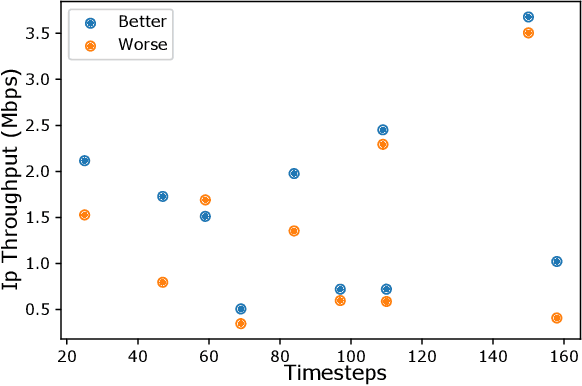
Communication load balancing aims to balance the load between different available resources, and thus improve the quality of service for network systems. After formulating the load balancing (LB) as a Markov decision process problem, reinforcement learning (RL) has recently proven effective in addressing the LB problem. To leverage the benefits of classical RL for load balancing, however, we need an explicit reward definition. Engineering this reward function is challenging, because it involves the need for expert knowledge and there lacks a general consensus on the form of an optimal reward function. In this work, we tackle the communication load balancing problem from an inverse reinforcement learning (IRL) approach. To the best of our knowledge, this is the first time IRL has been successfully applied in the field of communication load balancing. Specifically, first, we infer a reward function from a set of demonstrations, and then learn a reinforcement learning load balancing policy with the inferred reward function. Compared to classical RL-based solution, the proposed solution can be more general and more suitable for real-world scenarios. Experimental evaluations implemented on different simulated traffic scenarios have shown our method to be effective and better than other baselines by a considerable margin.
Policy Reuse for Communication Load Balancing in Unseen Traffic Scenarios
Mar 22, 2023With the continuous growth in communication network complexity and traffic volume, communication load balancing solutions are receiving increasing attention. Specifically, reinforcement learning (RL)-based methods have shown impressive performance compared with traditional rule-based methods. However, standard RL methods generally require an enormous amount of data to train, and generalize poorly to scenarios that are not encountered during training. We propose a policy reuse framework in which a policy selector chooses the most suitable pre-trained RL policy to execute based on the current traffic condition. Our method hinges on a policy bank composed of policies trained on a diverse set of traffic scenarios. When deploying to an unknown traffic scenario, we select a policy from the policy bank based on the similarity between the previous-day traffic of the current scenario and the traffic observed during training. Experiments demonstrate that this framework can outperform classical and adaptive rule-based methods by a large margin.
Human Motion Prediction via Pattern Completion in Latent Representation Space
Apr 18, 2019
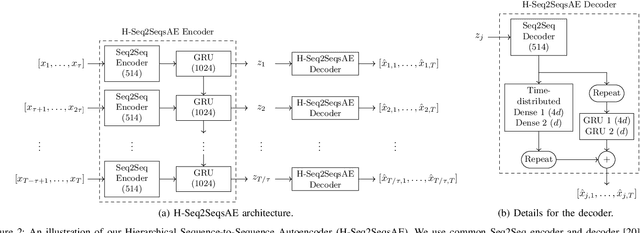
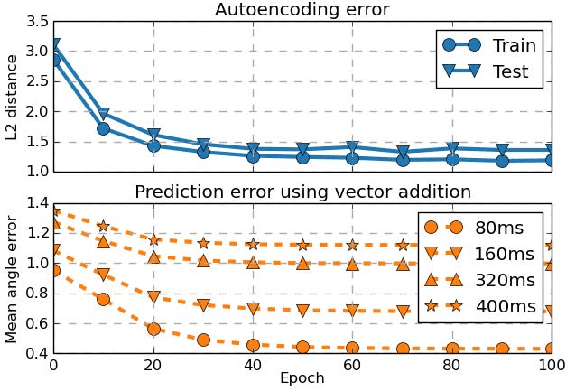

Inspired by ideas in cognitive science, we propose a novel and general approach to solve human motion understanding via pattern completion on a learned latent representation space. Our model outperforms current state-of-the-art methods in human motion prediction across a number of tasks, with no customization. To construct a latent representation for time-series of various lengths, we propose a new and generic autoencoder based on sequence-to-sequence learning. While traditional inference strategies find a correlation between an input and an output, we use pattern completion, which views the input as a partial pattern and to predict the best corresponding complete pattern. Our results demonstrate that this approach has advantages when combined with our autoencoder in solving human motion prediction, motion generation and action classification.