 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAs If We've Met Before: LLMs Exhibit Certainty in Recognizing Seen Files
Nov 19, 2025The remarkable language ability of Large Language Models (LLMs) stems from extensive training on vast datasets, often including copyrighted material, which raises serious concerns about unauthorized use. While Membership Inference Attacks (MIAs) offer potential solutions for detecting such violations, existing approaches face critical limitations and challenges due to LLMs' inherent overconfidence, limited access to ground truth training data, and reliance on empirically determined thresholds. We present COPYCHECK, a novel framework that leverages uncertainty signals to detect whether copyrighted content was used in LLM training sets. Our method turns LLM overconfidence from a limitation into an asset by capturing uncertainty patterns that reliably distinguish between ``seen" (training data) and ``unseen" (non-training data) content. COPYCHECK further implements a two-fold strategy: (1) strategic segmentation of files into smaller snippets to reduce dependence on large-scale training data, and (2) uncertainty-guided unsupervised clustering to eliminate the need for empirically tuned thresholds. Experiment results show that COPYCHECK achieves an average balanced accuracy of 90.1% on LLaMA 7b and 91.6% on LLaMA2 7b in detecting seen files. Compared to the SOTA baseline, COPYCHECK achieves over 90% relative improvement, reaching up to 93.8\% balanced accuracy. It further exhibits strong generalizability across architectures, maintaining high performance on GPT-J 6B. This work presents the first application of uncertainty for copyright detection in LLMs, offering practical tools for training data transparency.
RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation
May 24, 2024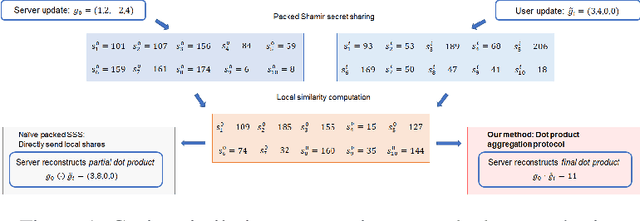

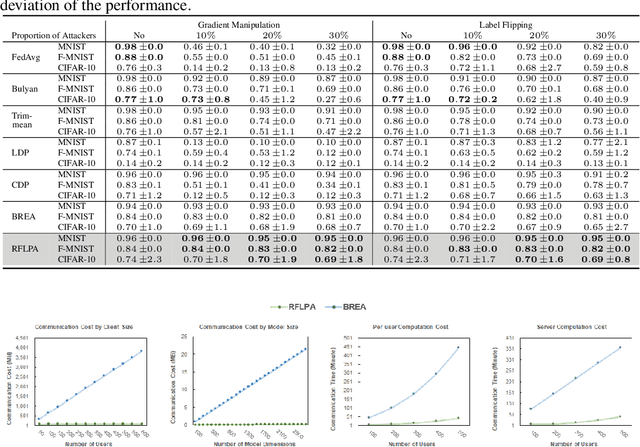
Federated learning (FL) allows multiple devices to train a model collaboratively without sharing their data. Despite its benefits, FL is vulnerable to privacy leakage and poisoning attacks. To address the privacy concern, secure aggregation (SecAgg) is often used to obtain the aggregation of gradients on sever without inspecting individual user updates. Unfortunately, existing defense strategies against poisoning attacks rely on the analysis of local updates in plaintext, making them incompatible with SecAgg. To reconcile the conflicts, we propose a robust federated learning framework against poisoning attacks (RFLPA) based on SecAgg protocol. Our framework computes the cosine similarity between local updates and server updates to conduct robust aggregation. Furthermore, we leverage verifiable packed Shamir secret sharing to achieve reduced communication cost of $O(M+N)$ per user, and design a novel dot-product aggregation algorithm to resolve the issue of increased information leakage. Our experimental results show that RFLPA significantly reduces communication and computation overhead by over $75\%$ compared to the state-of-the-art method, BREA, while maintaining competitive accuracy.
Teach Large Language Models to Forget Privacy
Dec 30, 2023



Large Language Models (LLMs) have proven powerful, but the risk of privacy leakage remains a significant concern. Traditional privacy-preserving methods, such as Differential Privacy and Homomorphic Encryption, are inadequate for black-box API-only settings, demanding either model transparency or heavy computational resources. We propose Prompt2Forget (P2F), the first framework designed to tackle the LLM local privacy challenge by teaching LLM to forget. The method involves decomposing full questions into smaller segments, generating fabricated answers, and obfuscating the model's memory of the original input. A benchmark dataset was crafted with questions containing privacy-sensitive information from diverse fields. P2F achieves zero-shot generalization, allowing adaptability across a wide range of use cases without manual adjustments. Experimental results indicate P2F's robust capability to obfuscate LLM's memory, attaining a forgetfulness score of around 90\% without any utility loss. This represents an enhancement of up to 63\% when contrasted with the naive direct instruction technique, highlighting P2F's efficacy in mitigating memory retention of sensitive information within LLMs. Our findings establish the first benchmark in the novel field of the LLM forgetting task, representing a meaningful advancement in privacy preservation in the emerging LLM domain.
Split-and-Denoise: Protect large language model inference with local differential privacy
Oct 13, 2023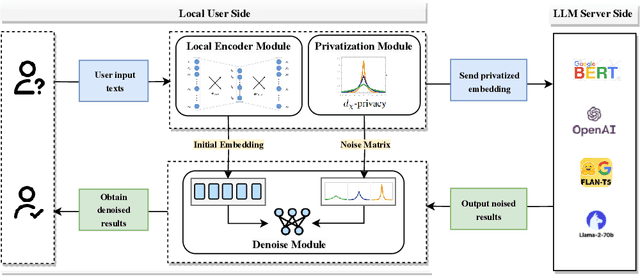
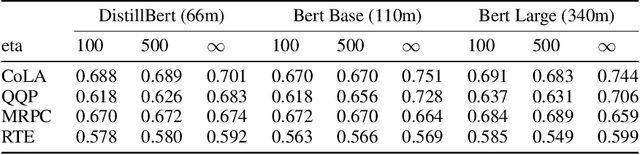
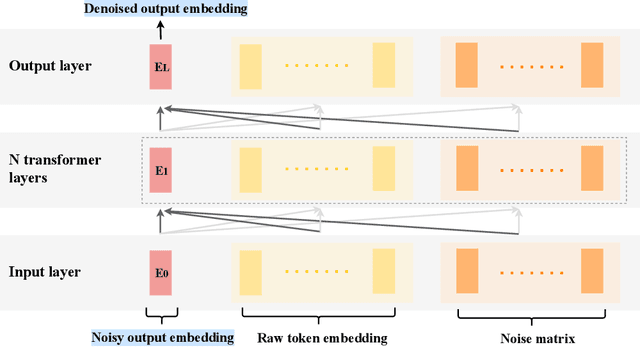

Large Language Models (LLMs) shows powerful capability in natural language understanding by capturing hidden semantics in vector space. This process enriches the value of the text embeddings for various downstream tasks, thereby fostering the Embedding-as-a-Service (EaaS) business model. However, the direct transmission of text to servers poses a largely unaddressed risk of privacy leakage. To mitigate this issue, we introduce Split-N-Denoise (SnD), an innovative framework that split the model to execute the token embedding layer on the client side at minimal computational cost. This allows the client to introduce noise prior to transmitting the embeddings to the server, and subsequently receive and denoise the perturbed output embeddings for downstream tasks. Our approach is designed for the inference stage of LLMs and requires no modifications to the model parameters. Extensive experiments demonstrate SnD's effectiveness in optimizing the privacy-utility tradeoff across various LLM architectures and diverse downstream tasks. The results reveal a significant performance improvement under the same privacy budget compared to the baseline, offering clients a privacy-preserving solution for local privacy protection.