 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGF: Unifying Local and Global Features for Visual Localization
Dec 23, 2022



Advanced visual localization techniques encompass image retrieval challenges and 6 Degree-of-Freedom (DoF) camera pose estimation, such as hierarchical localization. Thus, they must extract global and local features from input images. Previous methods have achieved this through resource-intensive or accuracy-reducing means, such as combinatorial pipelines or multi-task distillation. In this study, we present a novel method called SuperGF, which effectively unifies local and global features for visual localization, leading to a higher trade-off between localization accuracy and computational efficiency. Specifically, SuperGF is a transformer-based aggregation model that operates directly on image-matching-specific local features and generates global features for retrieval. We conduct experimental evaluations of our method in terms of both accuracy and efficiency, demonstrating its advantages over other methods. We also provide implementations of SuperGF using various types of local features, including dense and sparse learning-based or hand-crafted descriptors.
Matching in the Dark: A Dataset for Matching Image Pairs of Low-light Scenes
Sep 14, 2021
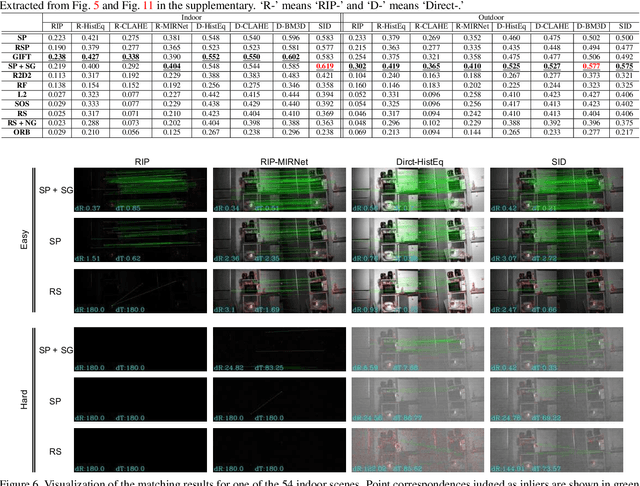


This paper considers matching images of low-light scenes, aiming to widen the frontier of SfM and visual SLAM applications. Recent image sensors can record the brightness of scenes with more than eight-bit precision, available in their RAW-format image. We are interested in making full use of such high-precision information to match extremely low-light scene images that conventional methods cannot handle. For extreme low-light scenes, even if some of their brightness information exists in the RAW format images' low bits, the standard raw image processing on cameras fails to utilize them properly. As was recently shown by Chen et al., CNNs can learn to produce images with a natural appearance from such RAW-format images. To consider if and how well we can utilize such information stored in RAW-format images for image matching, we have created a new dataset named MID (matching in the dark). Using it, we experimentally evaluated combinations of eight image-enhancing methods and eleven image matching methods consisting of classical/neural local descriptors and classical/neural initial point-matching methods. The results show the advantage of using the RAW-format images and the strengths and weaknesses of the above component methods. They also imply there is room for further research.