 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Few-Shot Early Rumor Detection with Imitation Agent
Dec 20, 2025Early Rumor Detection (EARD) aims to identify the earliest point at which a claim can be accurately classified based on a sequence of social media posts. This is especially challenging in data-scarce settings. While Large Language Models (LLMs) perform well in few-shot NLP tasks, they are not well-suited for time-series data and are computationally expensive for both training and inference. In this work, we propose a novel EARD framework that combines an autonomous agent and an LLM-based detection model, where the agent acts as a reliable decision-maker for \textit{early time point determination}, while the LLM serves as a powerful \textit{rumor detector}. This approach offers the first solution for few-shot EARD, necessitating only the training of a lightweight agent and allowing the LLM to remain training-free. Extensive experiments on four real-world datasets show our approach boosts performance across LLMs and surpasses existing EARD methods in accuracy and earliness.
Multimodal Misinformation Detection by Learning from Synthetic Data with Multimodal LLMs
Sep 29, 2024
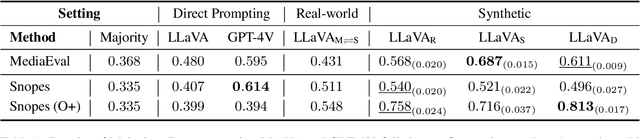
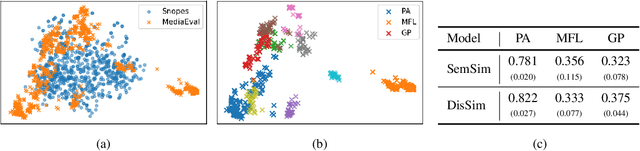
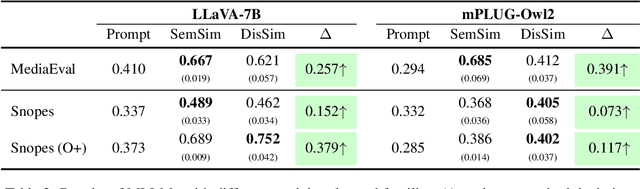
Detecting multimodal misinformation, especially in the form of image-text pairs, is crucial. Obtaining large-scale, high-quality real-world fact-checking datasets for training detectors is costly, leading researchers to use synthetic datasets generated by AI technologies. However, the generalizability of detectors trained on synthetic data to real-world scenarios remains unclear due to the distribution gap. To address this, we propose learning from synthetic data for detecting real-world multimodal misinformation through two model-agnostic data selection methods that match synthetic and real-world data distributions. Experiments show that our method enhances the performance of a small MLLM (13B) on real-world fact-checking datasets, enabling it to even surpass GPT-4V~\cite{GPT-4V}.
JustiLM: Few-shot Justification Generation for Explainable Fact-Checking of Real-world Claims
Jan 16, 2024Justification is an explanation that supports the veracity assigned to a claim in fact-checking. However, the task of justification generation is previously oversimplified as summarization of fact-check article authored by fact-checkers. Therefore, we propose a realistic approach to generate justification based on retrieved evidence. We present a new benchmark dataset called ExClaim for \underline{Ex}plainable fact-checking of real-world \underline{Claim}s, and introduce JustiLM, a novel few-shot \underline{Justi}fication generation based on retrieval-augmented \underline{L}anguage \underline{M}odel by using fact-check articles as auxiliary resource during training only. Experiments show that JustiLM achieves promising performance in justification generation compared to strong baselines, and can also enhance veracity classification with a straightforward extension.
Prompt to be Consistent is Better than Self-Consistent? Few-Shot and Zero-Shot Fact Verification with Pre-trained Language Models
Jun 05, 2023



Few-shot or zero-shot fact verification only relies on a few or no labeled training examples. In this paper, we propose a novel method called ProToCo, to \underline{Pro}mpt pre-trained language models (PLMs) \underline{To} be \underline{Co}nsistent, for improving the factuality assessment capability of PLMs in the few-shot and zero-shot settings. Given a claim-evidence pair, ProToCo generates multiple variants of the claim with different relations and frames a simple consistency mechanism as constraints for making compatible predictions across these variants. We update PLMs by using parameter-efficient fine-tuning (PEFT), leading to more accurate predictions in few-shot and zero-shot fact verification tasks. Our experiments on three public verification datasets show that ProToCo significantly outperforms state-of-the-art few-shot fact verification baselines. With a small number of unlabeled instances, ProToCo also outperforms the strong zero-shot learner T0 on zero-shot verification. Compared to large PLMs using in-context learning (ICL) method, ProToCo outperforms OPT-30B and the Self-Consistency-enabled OPT-6.7B model in both few- and zero-shot settings.
Early Rumor Detection Using Neural Hawkes Process with a New Benchmark Dataset
Jun 05, 2023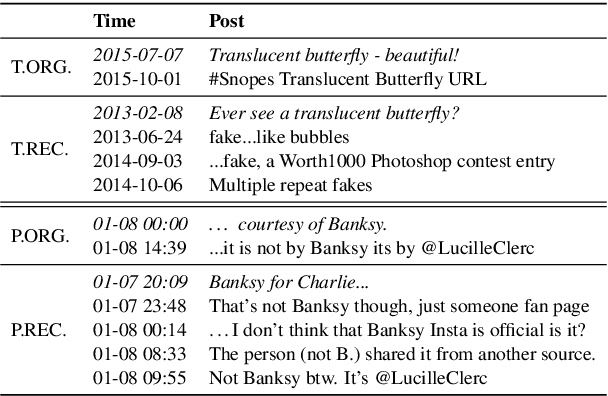
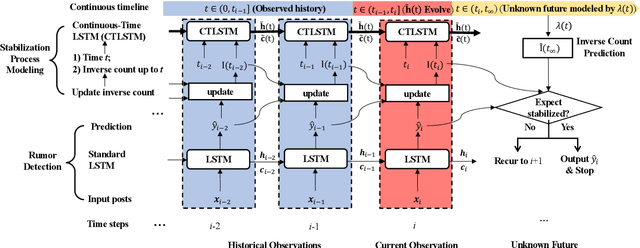
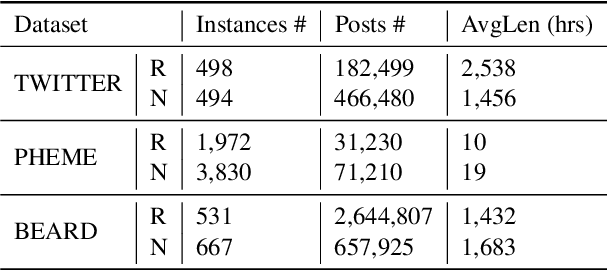

Little attention has been paid on \underline{EA}rly \underline{R}umor \underline{D}etection (EARD), and EARD performance was evaluated inappropriately on a few datasets where the actual early-stage information is largely missing. To reverse such situation, we construct BEARD, a new \underline{B}enchmark dataset for \underline{EARD}, based on claims from fact-checking websites by trying to gather as many early relevant posts as possible. We also propose HEARD, a novel model based on neural \underline{H}awkes process for \underline{EARD}, which can guide a generic rumor detection model to make timely, accurate and stable predictions. Experiments show that HEARD achieves effective EARD performance on two commonly used general rumor detection datasets and our BEARD dataset.