 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Rumor Detection Using Neural Hawkes Process with a New Benchmark Dataset
Paper and Code
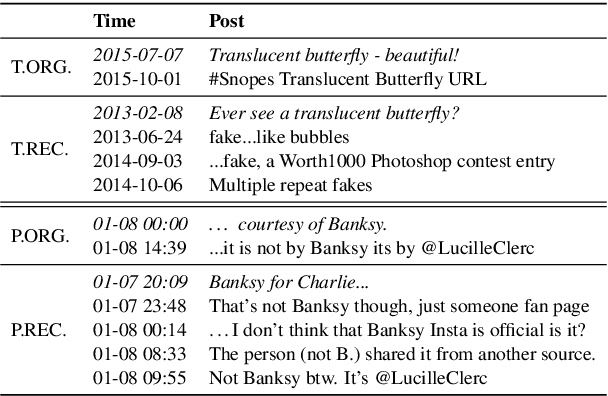
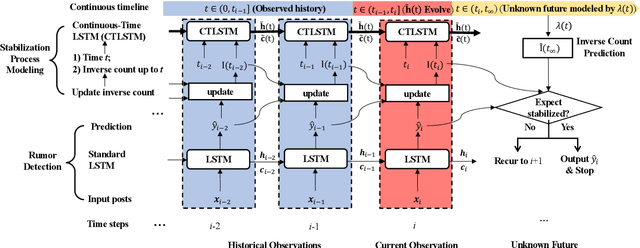
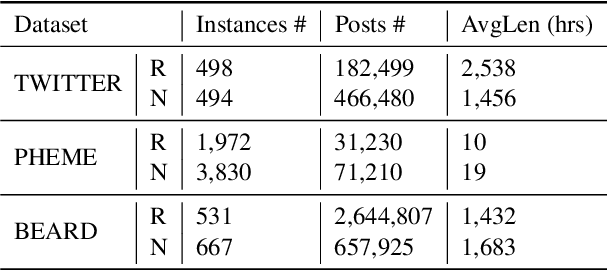

Little attention has been paid on \underline{EA}rly \underline{R}umor \underline{D}etection (EARD), and EARD performance was evaluated inappropriately on a few datasets where the actual early-stage information is largely missing. To reverse such situation, we construct BEARD, a new \underline{B}enchmark dataset for \underline{EARD}, based on claims from fact-checking websites by trying to gather as many early relevant posts as possible. We also propose HEARD, a novel model based on neural \underline{H}awkes process for \underline{EARD}, which can guide a generic rumor detection model to make timely, accurate and stable predictions. Experiments show that HEARD achieves effective EARD performance on two commonly used general rumor detection datasets and our BEARD dataset.