 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Few-Shot Learning in the Open World: A Review and Beyond
Aug 19, 2024



Human intelligence is characterized by our ability to absorb and apply knowledge from the world around us, especially in rapidly acquiring new concepts from minimal examples, underpinned by prior knowledge. Few-shot learning (FSL) aims to mimic this capacity by enabling significant generalizations and transferability. However, traditional FSL frameworks often rely on assumptions of clean, complete, and static data, conditions that are seldom met in real-world environments. Such assumptions falter in the inherently uncertain, incomplete, and dynamic contexts of the open world. This paper presents a comprehensive review of recent advancements designed to adapt FSL for use in open-world settings. We categorize existing methods into three distinct types of open-world few-shot learning: those involving varying instances, varying classes, and varying distributions. Each category is discussed in terms of its specific challenges and methods, as well as its strengths and weaknesses. We standardize experimental settings and metric benchmarks across scenarios, and provide a comparative analysis of the performance of various methods. In conclusion, we outline potential future research directions for this evolving field. It is our hope that this review will catalyze further development of effective solutions to these complex challenges, thereby advancing the field of artificial intelligence.
Scalable Label Distribution Learning for Multi-Label Classification
Nov 28, 2023
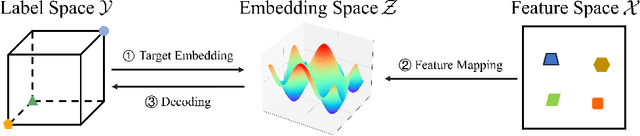
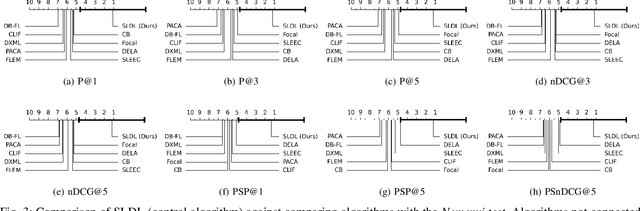
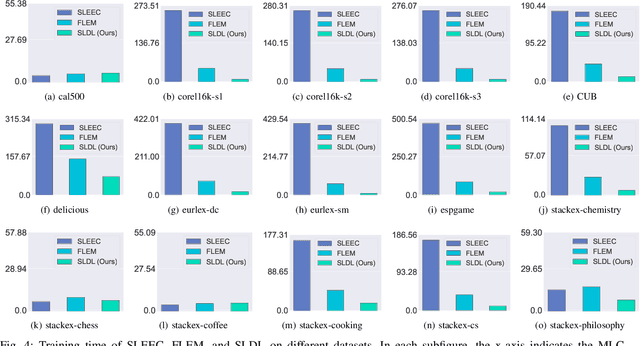
Multi-label classification (MLC) refers to the problem of tagging a given instance with a set of relevant labels. Most existing MLC methods are based on the assumption that the correlation of two labels in each label pair is symmetric, which is violated in many real-world scenarios. Moreover, most existing methods design learning processes associated with the number of labels, which makes their computational complexity a bottleneck when scaling up to large-scale output space. To tackle these issues, we propose a novel MLC learning method named Scalable Label Distribution Learning (SLDL) for multi-label classification which can describe different labels as distributions in a latent space, where the label correlation is asymmetric and the dimension is independent of the number of labels. Specifically, SLDL first converts labels into continuous distributions within a low-dimensional latent space and leverages the asymmetric metric to establish the correlation between different labels. Then, it learns the mapping from the feature space to the latent space, resulting in the computational complexity is no longer related to the number of labels. Finally, SLDL leverages a nearest-neighbor-based strategy to decode the latent representations and obtain the final predictions. Our extensive experiments illustrate that SLDL can achieve very competitive classification performances with little computational consumption.