 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Label Distribution Learning for Multi-Label Classification
Paper and Code

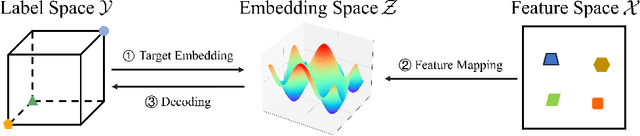
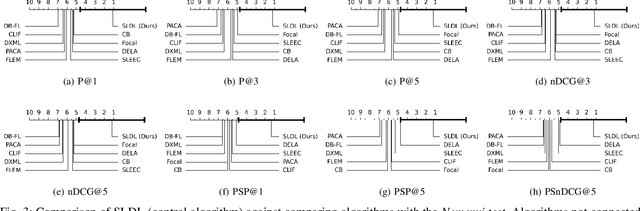
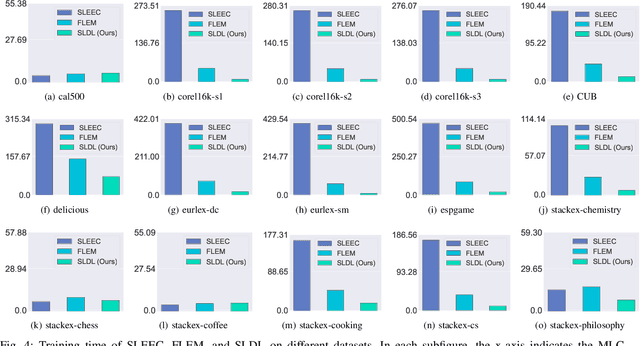
Multi-label classification (MLC) refers to the problem of tagging a given instance with a set of relevant labels. Most existing MLC methods are based on the assumption that the correlation of two labels in each label pair is symmetric, which is violated in many real-world scenarios. Moreover, most existing methods design learning processes associated with the number of labels, which makes their computational complexity a bottleneck when scaling up to large-scale output space. To tackle these issues, we propose a novel MLC learning method named Scalable Label Distribution Learning (SLDL) for multi-label classification which can describe different labels as distributions in a latent space, where the label correlation is asymmetric and the dimension is independent of the number of labels. Specifically, SLDL first converts labels into continuous distributions within a low-dimensional latent space and leverages the asymmetric metric to establish the correlation between different labels. Then, it learns the mapping from the feature space to the latent space, resulting in the computational complexity is no longer related to the number of labels. Finally, SLDL leverages a nearest-neighbor-based strategy to decode the latent representations and obtain the final predictions. Our extensive experiments illustrate that SLDL can achieve very competitive classification performances with little computational consumption.