 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust RGB-based 6-DoF Pose Estimation without Real Pose Annotations
Paper and Code
Aug 19, 2020
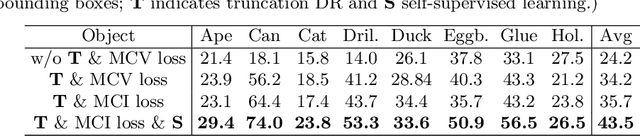
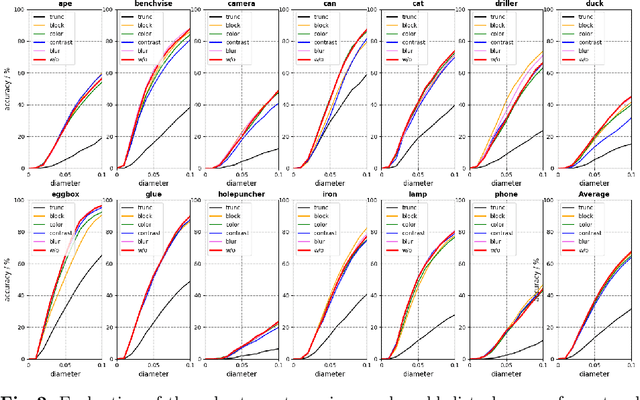

While much progress has been made in 6-DoF object pose estimation from a single RGB image, the current leading approaches heavily rely on real-annotation data. As such, they remain sensitive to severe occlusions, because covering all possible occlusions with annotated data is intractable. In this paper, we introduce an approach to robustly and accurately estimate the 6-DoF pose in challenging conditions and without using any real pose annotations. To this end, we leverage the intuition that the poses predicted by a network from an image and from its counterpart synthetically altered to mimic occlusion should be consistent, and translate this to a self-supervised loss function. Our experiments on LINEMOD, Occluded-LINEMOD, YCB and new Randomization LINEMOD dataset evidence the robustness of our approach. We achieve state of the art performance on LINEMOD, and OccludedLINEMOD in without real-pose setting, even outperforming methods that rely on real annotations during training on Occluded-LINEMOD.