 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Under Imperfect Compression: A Theory of Approximate MDL
Jun 03, 2026Minimum Description Length (MDL) formalizes the principle of Occam's razor by optimizing the total description length: $L(\mathrm{model})+L(\mathrm{data} \ | \ \mathrm{model})$. For sequential prediction, the MDL method repeatedly selects a model with a minimum objective score of the observed prefix for the next step prediction. Classical MDL prediction theory shows that exact optimization of the MDL objective indeed provides a strong compression guarantee that supports reliable prediction. However, practical machine learning usually can only find models by approximately optimizing the objective function. To bridge this gap, this paper addresses the following fundamental question: Under what forms of approximation and regularization does approximate MDL still guarantee reliable sequential prediction? This work offers a principled characterization. We prove that for any approximation with additive slack $C$ of the more general form of the balanced MDL objective: $λ\cdot L(\mathrm{model})+L(\mathrm{data} \ | \ \mathrm{model})$, the cumulative expected squared prediction error is finite for all $λ\ge1$. The case $λ>1$ is proved by an affinity-telescoping argument, while the boundary case $λ=1$ is proved by a likelihood-ratio stopping argument based on exact static MDL bounds. Our results establish that classical MDL regularization remains robust to any fixed additive optimization error. Furthermore, we establish that our characterization of the approximate MDL framework is sharp: When $0<λ<1$, overfits can happen to incur infinite cumulative expected error in the universal class of estimable measures, and hence a strong form of model-complexity regularization is necessary. In addition, model selection may fail in every regularized regime $λ>0$, under multiplicative approximation, and thus, additive approximation is both sufficient and essential.
Rethinking the Role of Positional Encoding: Sliding-Window Transformers without PE Remain Turing Complete
Jun 01, 2026Positional encoding (PE) is widely viewed as necessary for transformers to process ordered sequences: without them, the next-token map appears permutation-invariant in its context tokens. This intuition underlies all prior universality results, which rely on positional information to prove that transformers with chain-of-thought can perform arbitrary computation, i.e., they are Turing complete. We revisit this belief in the regime most relevant to long-form reasoning, where generation proceeds through a finite sliding context window. Our opening perception is that the window mechanism itself (mildly) breaks the permutation symmetry. To distill and precisely capture the degree of this added expressiveness, we introduce an abstract autoregressive model, the HIST model, in which each update depends only on constant-size internal state and the token-count histogram within the current window. We prove that this HIST model is Turing complete by showing that the evolution of the window can reveal the token that has just left the window, which suffices to simulate Turing-complete Post machines. We then construct a sliding-window transformer over a constant-size token alphabet, without PE, and show that it can simulate the HIST model. Our result demonstrates that positional encodings are not indispensable for transformers to perform universal computation: The window sliding itself already breaks permutation symmetry and captures sufficient positional information.
Seeing the Scene Matters: Revealing Forgetting in Video Understanding Models with a Scene-Aware Long-Video Benchmark
Mar 28, 2026Long video understanding (LVU) remains a core challenge in multimodal learning. Although recent vision-language models (VLMs) have made notable progress, existing benchmarks mainly focus on either fine-grained perception or coarse summarization, offering limited insight into temporal understanding over long contexts. In this work, we define a scene as a coherent segment of a video in which both visual and semantic contexts remain consistent, aligning with human perception. This leads us to a key question: can current VLMs reason effectively over long, scene-level contexts? To answer this, we introduce a new benchmark, SceneBench, designed to provide scene-level challenges. Our evaluation reveals a sharp drop in accuracy when VLMs attempt to answer scene-level questions, indicating significant forgetting of long-range context. To further validate these findings, we propose Scene Retrieval-Augmented Generation (Scene-RAG), which constructs a dynamic scene memory by retrieving and integrating relevant context across scenes. This Scene-RAG improves VLM performance by +2.50%, confirming that current models still struggle with long-context retention. We hope SceneBench will encourage future research toward VLMs with more robust, human-like video comprehension.
Provably Safe Trajectory Generation for Manipulators Under Motion and Environmental Uncertainties
Mar 10, 2026Robot manipulators operating in uncertain and non-convex environments present significant challenges for safe and optimal motion planning. Existing methods often struggle to provide efficient and formally certified collision risk guarantees, particularly when dealing with complex geometries and non-Gaussian uncertainties. This article proposes a novel risk-bounded motion planning framework to address this unmet need. Our approach integrates a rigid manipulator deep stochastic Koopman operator (RM-DeSKO) model to robustly predict the robot's state distribution under motion uncertainty. We then introduce an efficient, hierarchical verification method that combines parallelizable physics simulations with sum-of-squares (SOS) programming as a filter for fine-grained, formal certification of collision risk. This method is embedded within a Model Predictive Path Integral (MPPI) controller that uniquely utilizes binary collision information from SOS decomposition to improve its policy. The effectiveness of the proposed framework is validated on two typical robot manipulators through extensive simulations and real-world experiments, including a challenging human-robot collaboration scenario, demonstrating sim-to-real transfer of the learned model and its ability to generate safe and efficient trajectories in complex, uncertain settings.
AiReview: An Open Platform for Accelerating Systematic Reviews with LLMs
Apr 05, 2025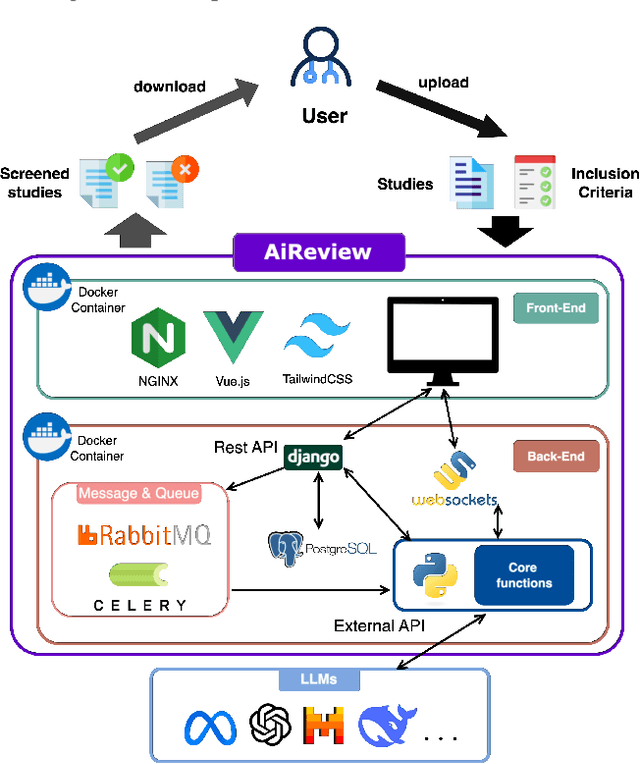
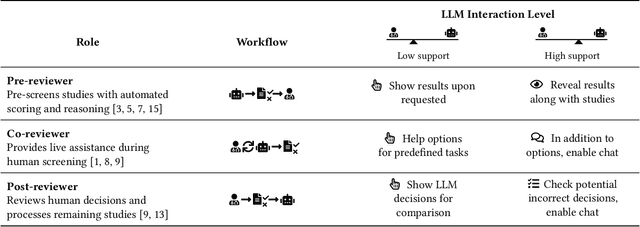
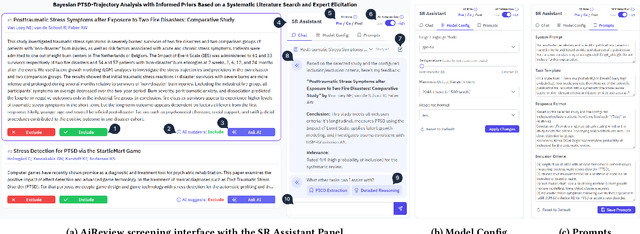
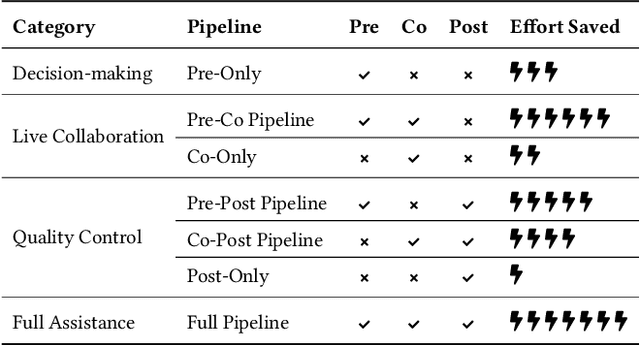
Systematic reviews are fundamental to evidence-based medicine. Creating one is time-consuming and labour-intensive, mainly due to the need to screen, or assess, many studies for inclusion in the review. Several tools have been developed to streamline this process, mostly relying on traditional machine learning methods. Large language models (LLMs) have shown potential in further accelerating the screening process. However, no tool currently allows end users to directly leverage LLMs for screening or facilitates systematic and transparent usage of LLM-assisted screening methods. This paper introduces (i) an extensible framework for applying LLMs to systematic review tasks, particularly title and abstract screening, and (ii) a web-based interface for LLM-assisted screening. Together, these elements form AiReview-a novel platform for LLM-assisted systematic review creation. AiReview is the first of its kind to bridge the gap between cutting-edge LLM-assisted screening methods and those that create medical systematic reviews. The tool is available at https://aireview.ielab.io. The source code is also open sourced at https://github.com/ielab/ai-review.
DenseReviewer: A Screening Prioritisation Tool for Systematic Review based on Dense Retrieval
Feb 05, 2025Screening is a time-consuming and labour-intensive yet required task for medical systematic reviews, as tens of thousands of studies often need to be screened. Prioritising relevant studies to be screened allows downstream systematic review creation tasks to start earlier and save time. In previous work, we developed a dense retrieval method to prioritise relevant studies with reviewer feedback during the title and abstract screening stage. Our method outperforms previous active learning methods in both effectiveness and efficiency. In this demo, we extend this prior work by creating (1) a web-based screening tool that enables end-users to screen studies exploiting state-of-the-art methods and (2) a Python library that integrates models and feedback mechanisms and allows researchers to develop and demonstrate new active learning methods. We describe the tool's design and showcase how it can aid screening. The tool is available at https://densereviewer.ielab.io. The source code is also open sourced at https://github.com/ielab/densereviewer.
Procedural Content Generation via Generative Artificial Intelligence
Jul 12, 2024The attempt to utilize machine learning in PCG has been made in the past. In this survey paper, we investigate how generative artificial intelligence (AI), which saw a significant increase in interest in the mid-2010s, is being used for PCG. We review applications of generative AI for the creation of various types of content, including terrains, items, and even storylines. While generative AI is effective for PCG, one significant issues it faces is that building high-performance generative AI requires vast amounts of training data. Because content generally highly customized, domain-specific training data is scarce, and straightforward approaches to generative AI models may not work well. For PCG research to advance further, issues related to limited training data must be overcome. Thus, we also give special consideration to research that addresses the challenges posed by limited training data.
Dense Retrieval with Continuous Explicit Feedback for Systematic Review Screening Prioritisation
Jun 30, 2024


The goal of screening prioritisation in systematic reviews is to identify relevant documents with high recall and rank them in early positions for review. This saves reviewing effort if paired with a stopping criterion, and speeds up review completion if performed alongside downstream tasks. Recent studies have shown that neural models have good potential on this task, but their time-consuming fine-tuning and inference discourage their widespread use for screening prioritisation. In this paper, we propose an alternative approach that still relies on neural models, but leverages dense representations and relevance feedback to enhance screening prioritisation, without the need for costly model fine-tuning and inference. This method exploits continuous relevance feedback from reviewers during document screening to efficiently update the dense query representation, which is then applied to rank the remaining documents to be screened. We evaluate this approach across the CLEF TAR datasets for this task. Results suggest that the investigated dense query-driven approach is more efficient than directly using neural models and shows promising effectiveness compared to previous methods developed on the considered datasets. Our code is available at https://github.com/ielab/dense-screening-feedback.
A Reproducibility Study of Goldilocks: Just-Right Tuning of BERT for TAR
Jan 16, 2024Screening documents is a tedious and time-consuming aspect of high-recall retrieval tasks, such as compiling a systematic literature review, where the goal is to identify all relevant documents for a topic. To help streamline this process, many Technology-Assisted Review (TAR) methods leverage active learning techniques to reduce the number of documents requiring review. BERT-based models have shown high effectiveness in text classification, leading to interest in their potential use in TAR workflows. In this paper, we investigate recent work that examined the impact of further pre-training epochs on the effectiveness and efficiency of a BERT-based active learning pipeline. We first report that we could replicate the original experiments on two specific TAR datasets, confirming some of the findings: importantly, that further pre-training is critical to high effectiveness, but requires attention in terms of selecting the correct training epoch. We then investigate the generalisability of the pipeline on a different TAR task, that of medical systematic reviews. In this context, we show that there is no need for further pre-training if a domain-specific BERT backbone is used within the active learning pipeline. This finding provides practical implications for using the studied active learning pipeline within domain-specific TAR tasks.
On the Power of SVD in the Stochastic Block Model
Sep 27, 2023A popular heuristic method for improving clustering results is to apply dimensionality reduction before running clustering algorithms. It has been observed that spectral-based dimensionality reduction tools, such as PCA or SVD, improve the performance of clustering algorithms in many applications. This phenomenon indicates that spectral method not only serves as a dimensionality reduction tool, but also contributes to the clustering procedure in some sense. It is an interesting question to understand the behavior of spectral steps in clustering problems. As an initial step in this direction, this paper studies the power of vanilla-SVD algorithm in the stochastic block model (SBM). We show that, in the symmetric setting, vanilla-SVD algorithm recovers all clusters correctly. This result answers an open question posed by Van Vu (Combinatorics Probability and Computing, 2018) in the symmetric setting.