 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOHO: Learning Single-view Hand-held Object Reconstruction with Multi-view Occlusion-Aware Supervision
Paper and Code
Oct 18, 2023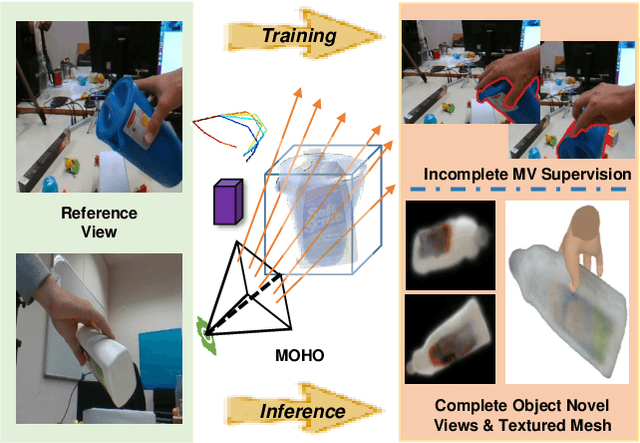
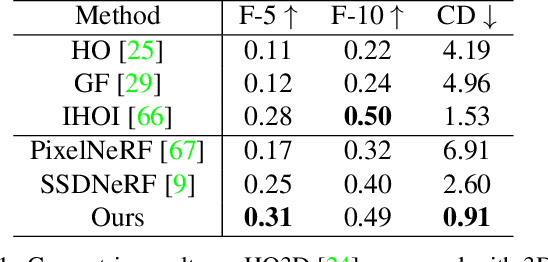
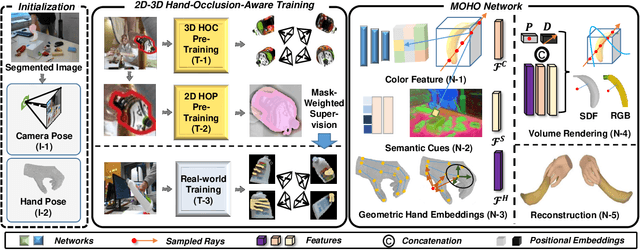
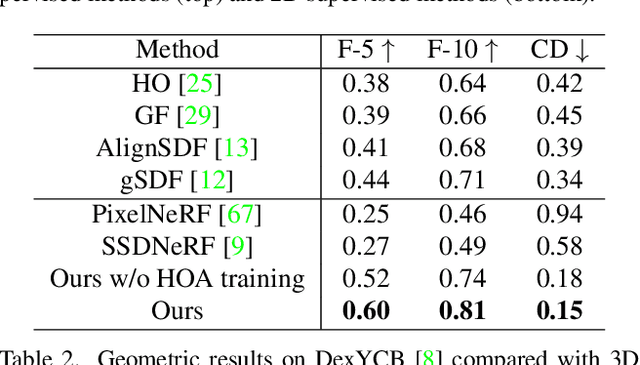
Previous works concerning single-view hand-held object reconstruction typically utilize supervision from 3D ground truth models, which are hard to collect in real world. In contrast, abundant videos depicting hand-object interactions can be accessed easily with low cost, although they only give partial object observations with complex occlusion. In this paper, we present MOHO to reconstruct hand-held object from a single image with multi-view supervision from hand-object videos, tackling two predominant challenges including object's self-occlusion and hand-induced occlusion. MOHO inputs semantic features indicating visible object parts and geometric embeddings provided by hand articulations as partial-to-full cues to resist object's self-occlusion, so as to recover full shape of the object. Meanwhile, a novel 2D-3D hand-occlusion-aware training scheme following the synthetic-to-real paradigm is proposed to release hand-induced occlusion. In the synthetic pre-training stage, 2D-3D hand-object correlations are constructed by supervising MOHO with rendered images to complete the hand-concealed regions of the object in both 2D and 3D space. Subsequently, MOHO is finetuned in real world by the mask-weighted volume rendering supervision adopting hand-object correlations obtained during pre-training. Extensive experiments on HO3D and DexYCB datasets demonstrate that 2D-supervised MOHO gains superior results against 3D-supervised methods by a large margin. Codes and key assets will be released soon.