 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Self-Learning for Multi-Source Domain Adaptation: A Benchmark
Aug 24, 2021
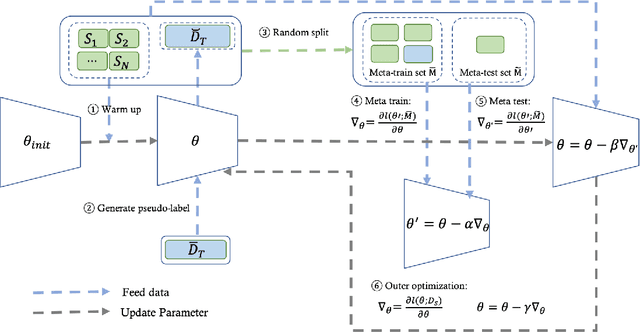

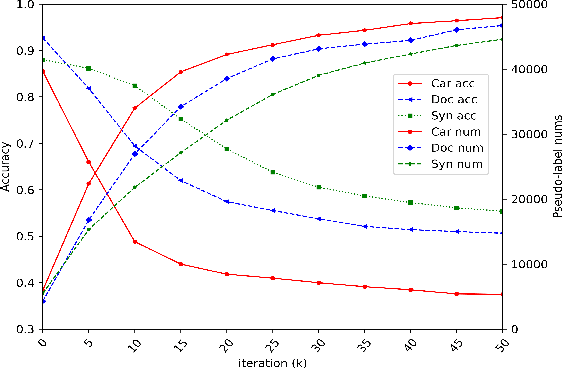
In recent years, deep learning-based methods have shown promising results in computer vision area. However, a common deep learning model requires a large amount of labeled data, which is labor-intensive to collect and label. What's more, the model can be ruined due to the domain shift between training data and testing data. Text recognition is a broadly studied field in computer vision and suffers from the same problems noted above due to the diversity of fonts and complicated backgrounds. In this paper, we focus on the text recognition problem and mainly make three contributions toward these problems. First, we collect a multi-source domain adaptation dataset for text recognition, including five different domains with over five million images, which is the first multi-domain text recognition dataset to our best knowledge. Secondly, we propose a new method called Meta Self-Learning, which combines the self-learning method with the meta-learning paradigm and achieves a better recognition result under the scene of multi-domain adaptation. Thirdly, extensive experiments are conducted on the dataset to provide a benchmark and also show the effectiveness of our method. The code of our work and dataset are available soon at https://bupt-ai-cz.github.io/Meta-SelfLearning/.