 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025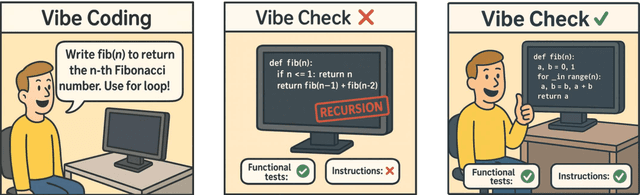
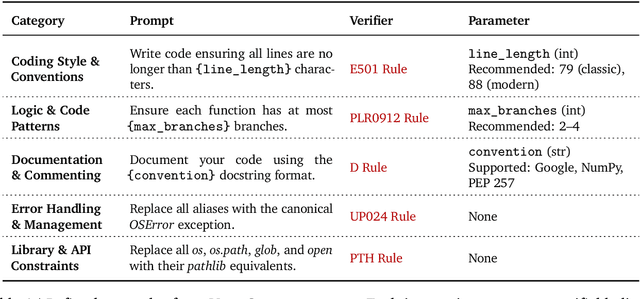
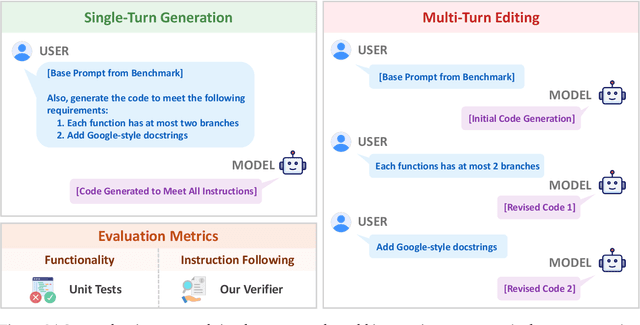
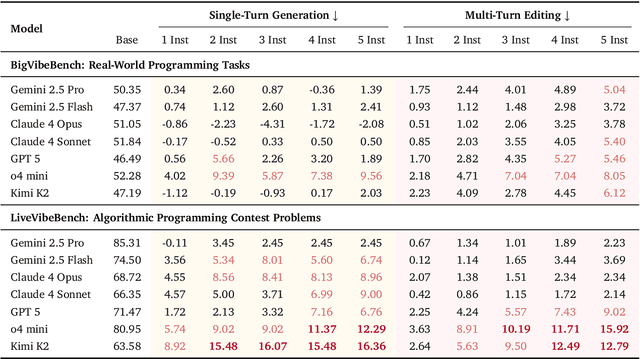
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
Jun 19, 2024



This paper studies in-context learning (ICL) by decomposing the output of large language models into the individual contributions of attention heads and MLPs (components). We observe curious components: good-performing ones that individually do well on a classification task, even when the model performs poorly; bad-performing ones that do much worse than chance; and label-biased components that always predict the same label. We find that component accuracies are well-correlated across different demonstration sets and perturbations of prompt templates, even when the full-model accuracy varies greatly. Based on our findings, we propose component reweighting, which learns to linearly re-scale the component activations from a few labeled examples. Given 24 labeled examples, our method improves by an average of 6.0% accuracy points over 24-shot ICL across 8 tasks on Llama-2-7B. Overall, this paper both enriches our understanding of ICL and provides a practical method for improvement by examining model internals.
Do Localization Methods Actually Localize Memorized Data in LLMs?
Nov 15, 2023



Large language models (LLMs) can memorize many pretrained sequences verbatim. This paper studies if we can locate a small set of neurons in LLMs responsible for memorizing a given sequence. While the concept of localization is often mentioned in prior work, methods for localization have never been systematically and directly evaluated; we address this with two benchmarking approaches. In our INJ Benchmark, we actively inject a piece of new information into a small subset of LLM weights and measure whether localization methods can identify these "ground truth" weights. In the DEL Benchmark, we study localization of pretrained data that LLMs have already memorized; while this setting lacks ground truth, we can still evaluate localization by measuring whether dropping out located neurons erases a memorized sequence from the model. We evaluate five localization methods on our two benchmarks, and both show similar rankings. All methods exhibit promising localization ability, especially for pruning-based methods, though the neurons they identify are not necessarily specific to a single memorized sequence.
Careful Data Curation Stabilizes In-context Learning
Dec 20, 2022In-context learning (ICL) enables large language models (LLMs) to perform new tasks by prompting them with a sequence of training examples. However, ICL is very sensitive to the choice of training examples: randomly sampling examples from a training set leads to high variance in performance. In this paper, we show that curating a carefully chosen subset of training data greatly stabilizes ICL performance. We propose two methods to choose training subsets, both of which score training examples individually and then select the highest-scoring ones. CondAcc scores a training example by its average ICL accuracy when combined with random training examples, while Datamodels learns a linear proxy model that estimates how the presence of each training example influences LLM accuracy. On average, CondAcc and Datamodels outperform sampling from the entire training set by 7.7% and 6.3%, respectively, across 5 tasks and two LLMs. Our analysis shows that stable subset examples are no more diverse than average, and are not outliers in terms of sequence length and perplexity.
CLiMB: A Continual Learning Benchmark for Vision-and-Language Tasks
Jun 18, 2022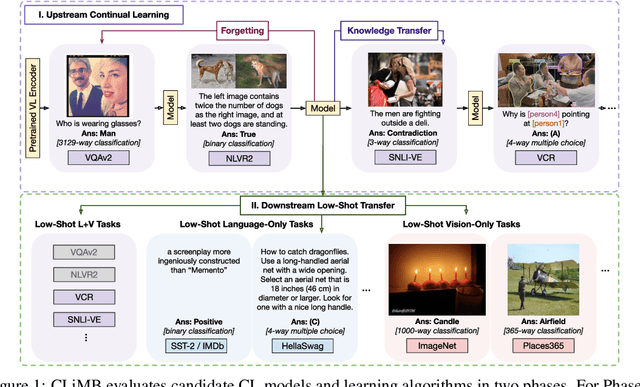
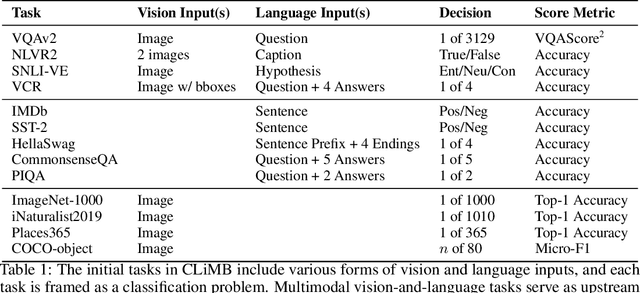

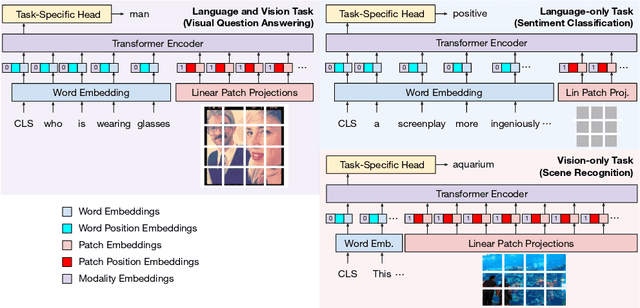
Current state-of-the-art vision-and-language models are evaluated on tasks either individually or in a multi-task setting, overlooking the challenges of continually learning (CL) tasks as they arrive. Existing CL benchmarks have facilitated research on task adaptation and mitigating "catastrophic forgetting", but are limited to vision-only and language-only tasks. We present CLiMB, a benchmark to study the challenge of learning multimodal tasks in a CL setting, and to systematically evaluate how upstream continual learning can rapidly generalize to new multimodal and unimodal tasks. CLiMB includes implementations of several CL algorithms and a modified Vision-Language Transformer (ViLT) model that can be deployed on both multimodal and unimodal tasks. We find that common CL methods can help mitigate forgetting during multimodal task learning, but do not enable cross-task knowledge transfer. We envision that CLiMB will facilitate research on a new class of CL algorithms for this challenging multimodal setting.
Rethinking Why Intermediate-Task Fine-Tuning Works
Sep 01, 2021

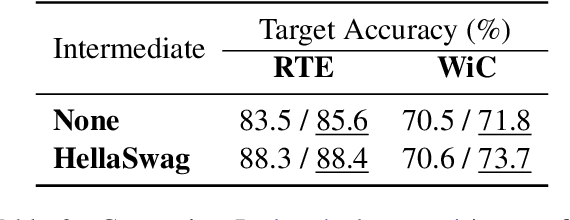
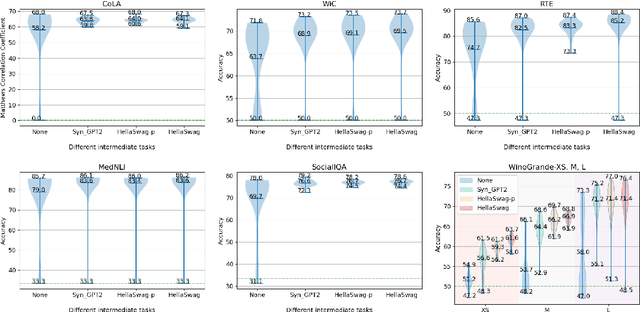
Supplementary Training on Intermediate Labeled-data Tasks (STILTs) is a widely applied technique, which first fine-tunes the pretrained language models on an intermediate task before on the target task of interest. While STILTs is able to further improve the performance of pretrained language models, it is still unclear why and when it works. Previous research shows that those intermediate tasks involving complex inference, such as commonsense reasoning, work especially well for RoBERTa. In this paper, we discover that the improvement from an intermediate task could be orthogonal to it containing reasoning or other complex skills -- a simple real-fake discrimination task synthesized by GPT2 can benefit diverse target tasks. We conduct extensive experiments to study the impact of different factors on STILTs. These findings suggest rethinking the role of intermediate fine-tuning in the STILTs pipeline.
Go Beyond Plain Fine-tuning: Improving Pretrained Models for Social Commonsense
May 12, 2021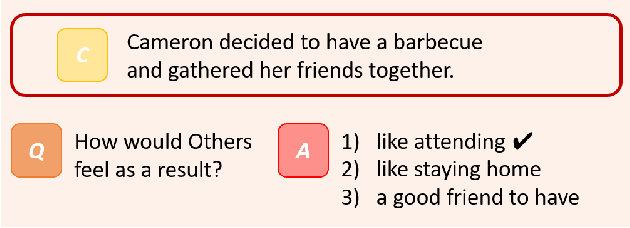
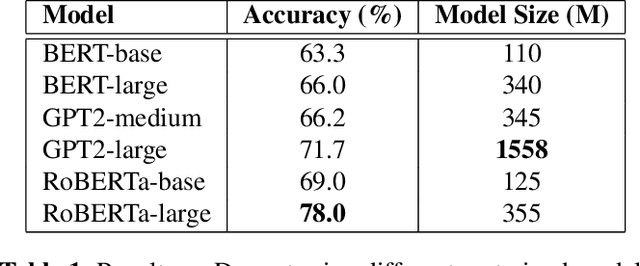
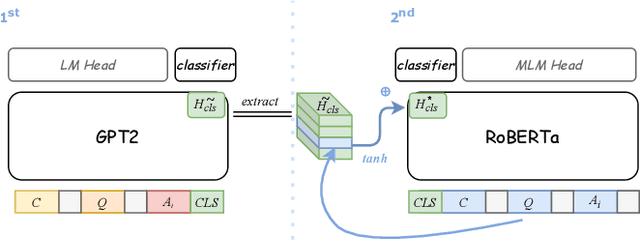
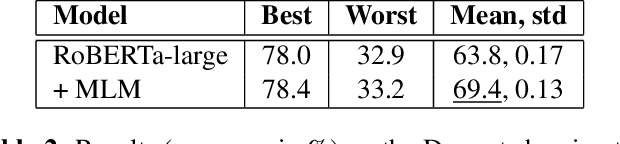
Pretrained language models have demonstrated outstanding performance in many NLP tasks recently. However, their social intelligence, which requires commonsense reasoning about the current situation and mental states of others, is still developing. Towards improving language models' social intelligence, we focus on the Social IQA dataset, a task requiring social and emotional commonsense reasoning. Building on top of the pretrained RoBERTa and GPT2 models, we propose several architecture variations and extensions, as well as leveraging external commonsense corpora, to optimize the model for Social IQA. Our proposed system achieves competitive results as those top-ranking models on the leaderboard. This work demonstrates the strengths of pretrained language models, and provides viable ways to improve their performance for a particular task.
Incorporating Commonsense Knowledge Graph in Pretrained Models for Social Commonsense Tasks
May 12, 2021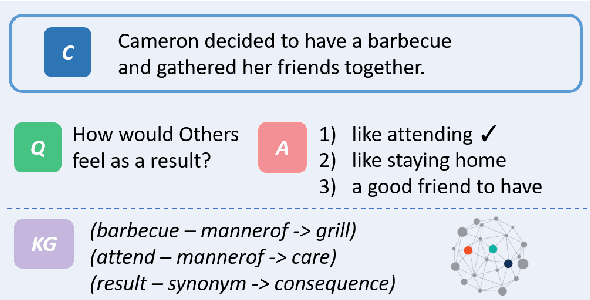
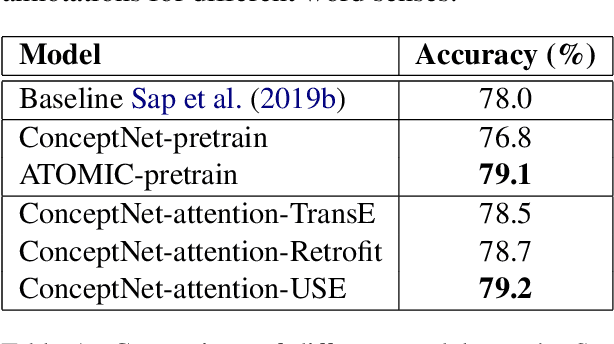
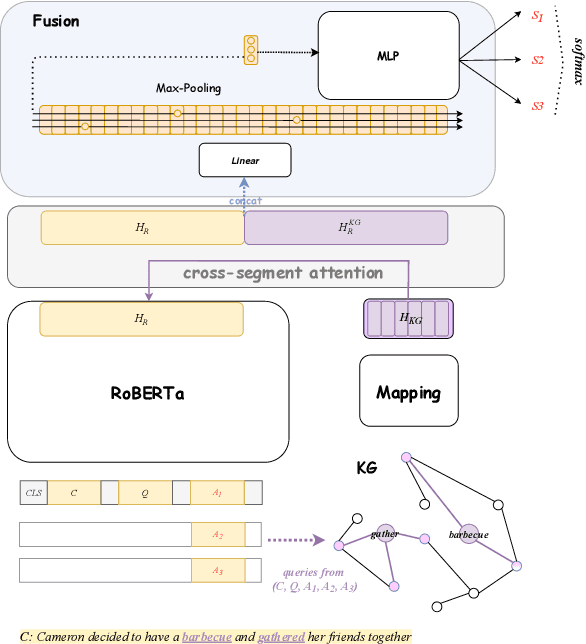
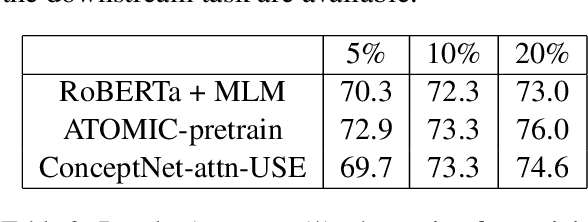
Pretrained language models have excelled at many NLP tasks recently; however, their social intelligence is still unsatisfactory. To enable this, machines need to have a more general understanding of our complicated world and develop the ability to perform commonsense reasoning besides fitting the specific downstream tasks. External commonsense knowledge graphs (KGs), such as ConceptNet, provide rich information about words and their relationships. Thus, towards general commonsense learning, we propose two approaches to \emph{implicitly} and \emph{explicitly} infuse such KGs into pretrained language models. We demonstrate our proposed methods perform well on SocialIQA, a social commonsense reasoning task, in both limited and full training data regimes.
TinyGAN: Distilling BigGAN for Conditional Image Generation
Sep 29, 2020
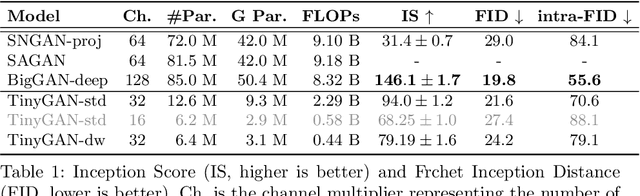

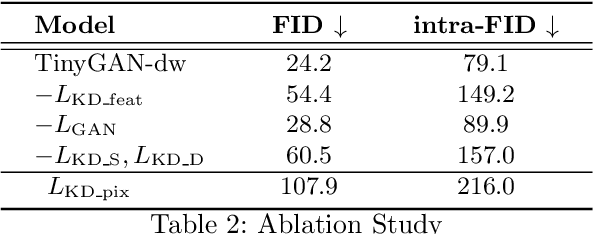
Generative Adversarial Networks (GANs) have become a powerful approach for generative image modeling. However, GANs are notorious for their training instability, especially on large-scale, complex datasets. While the recent work of BigGAN has significantly improved the quality of image generation on ImageNet, it requires a huge model, making it hard to deploy on resource-constrained devices. To reduce the model size, we propose a black-box knowledge distillation framework for compressing GANs, which highlights a stable and efficient training process. Given BigGAN as the teacher network, we manage to train a much smaller student network to mimic its functionality, achieving competitive performance on Inception and FID scores with the generator having $16\times$ fewer parameters.
xSense: Learning Sense-Separated Sparse Representations and Textual Definitions for Explainable Word Sense Networks
Sep 10, 2018
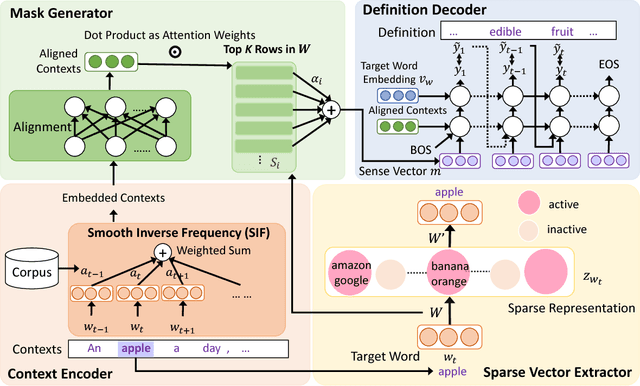
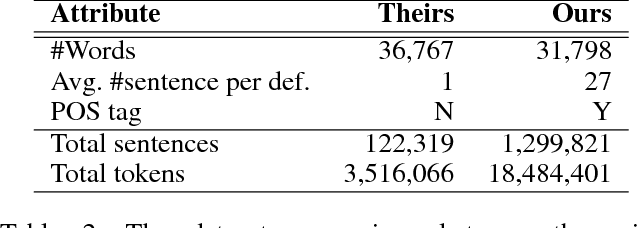
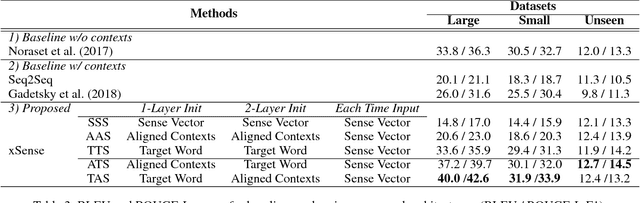
Despite the success achieved on various natural language processing tasks, word embeddings are difficult to interpret due to the dense vector representations. This paper focuses on interpreting the embeddings for various aspects, including sense separation in the vector dimensions and definition generation. Specifically, given a context together with a target word, our algorithm first projects the target word embedding to a high-dimensional sparse vector and picks the specific dimensions that can best explain the semantic meaning of the target word by the encoded contextual information, where the sense of the target word can be indirectly inferred. Finally, our algorithm applies an RNN to generate the textual definition of the target word in the human readable form, which enables direct interpretation of the corresponding word embedding. This paper also introduces a large and high-quality context-definition dataset that consists of sense definitions together with multiple example sentences per polysemous word, which is a valuable resource for definition modeling and word sense disambiguation. The conducted experiments show the superior performance in BLEU score and the human evaluation test.