 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Why Intermediate-Task Fine-Tuning Works
Paper and Code


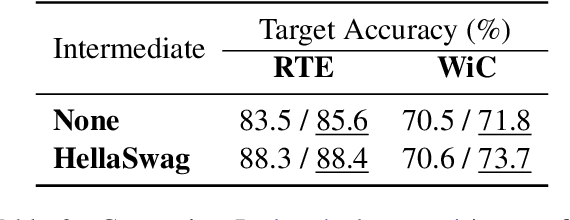
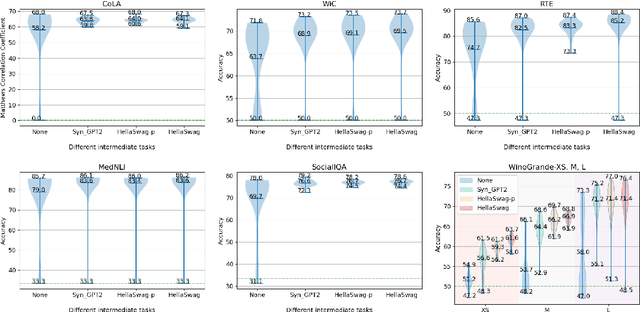
Supplementary Training on Intermediate Labeled-data Tasks (STILTs) is a widely applied technique, which first fine-tunes the pretrained language models on an intermediate task before on the target task of interest. While STILTs is able to further improve the performance of pretrained language models, it is still unclear why and when it works. Previous research shows that those intermediate tasks involving complex inference, such as commonsense reasoning, work especially well for RoBERTa. In this paper, we discover that the improvement from an intermediate task could be orthogonal to it containing reasoning or other complex skills -- a simple real-fake discrimination task synthesized by GPT2 can benefit diverse target tasks. We conduct extensive experiments to study the impact of different factors on STILTs. These findings suggest rethinking the role of intermediate fine-tuning in the STILTs pipeline.