 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Knowledge Delivery and Emotional Comfort in Healthcare Conversational Systems
Jun 16, 2025With the advancement of large language models, many dialogue systems are now capable of providing reasonable and informative responses to patients' medical conditions. However, when patients consult their doctor, they may experience negative emotions due to the severity and urgency of their situation. If the model can provide appropriate comfort and empathy based on the patient's negative emotions while answering medical questions, it will likely offer a more reassuring experience during the medical consultation process. To address this issue, our paper explores the balance between knowledge sharing and emotional support in the healthcare dialogue process. We utilize a large language model to rewrite a real-world interactive medical dialogue dataset, generating patient queries with negative emotions and corresponding medical responses aimed at soothing the patient's emotions while addressing their concerns. The modified data serves to refine the latest large language models with various fine-tuning methods, enabling them to accurately provide sentences with both emotional reassurance and constructive suggestions in response to patients' questions. Compared to the original LLM model, our experimental results demonstrate that our methodology significantly enhances the model's ability to generate emotional responses while maintaining its original capability to provide accurate knowledge-based answers.
PLM-ICD: Automatic ICD Coding with Pretrained Language Models
Jul 12, 2022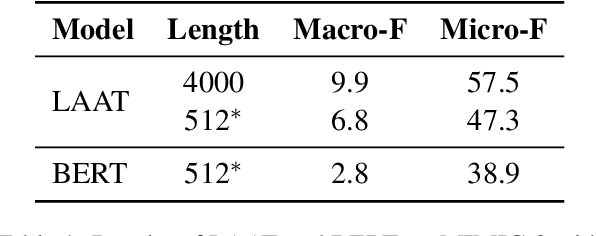
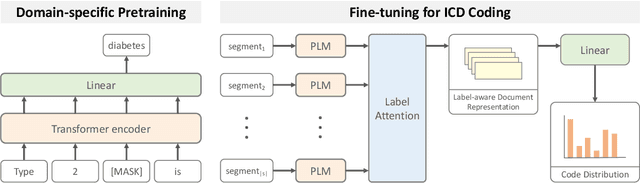
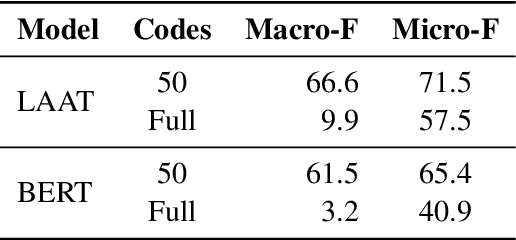
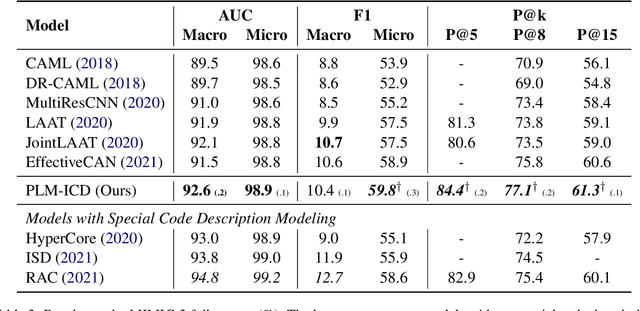
Automatically classifying electronic health records (EHRs) into diagnostic codes has been challenging to the NLP community. State-of-the-art methods treated this problem as a multilabel classification problem and proposed various architectures to model this problem. However, these systems did not leverage the superb performance of pretrained language models, which achieved superb performance on natural language understanding tasks. Prior work has shown that pretrained language models underperformed on this task with the regular finetuning scheme. Therefore, this paper aims at analyzing the causes of the underperformance and developing a framework for automatic ICD coding with pretrained language models. We spotted three main issues through the experiments: 1) large label space, 2) long input sequences, and 3) domain mismatch between pretraining and fine-tuning. We propose PLMICD, a framework that tackles the challenges with various strategies. The experimental results show that our proposed framework can overcome the challenges and achieves state-of-the-art performance in terms of multiple metrics on the benchmark MIMIC data. The source code is available at https://github.com/MiuLab/PLM-ICD
Modeling Diagnostic Label Correlation for Automatic ICD Coding
Jun 24, 2021
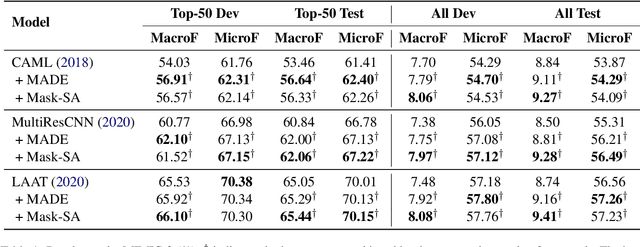
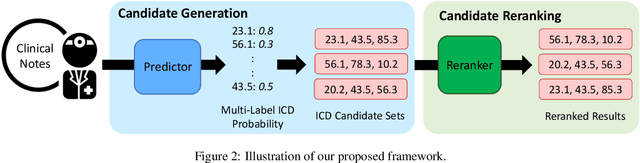
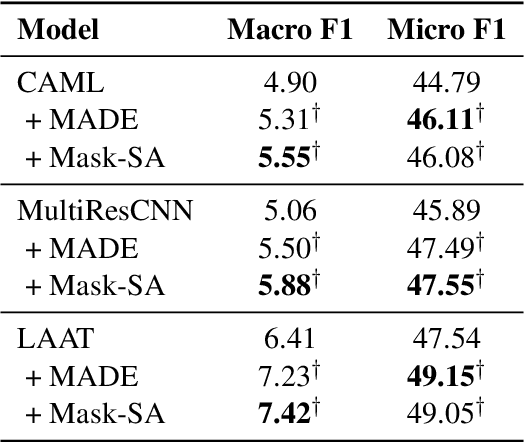
Given the clinical notes written in electronic health records (EHRs), it is challenging to predict the diagnostic codes which is formulated as a multi-label classification task. The large set of labels, the hierarchical dependency, and the imbalanced data make this prediction task extremely hard. Most existing work built a binary prediction for each label independently, ignoring the dependencies between labels. To address this problem, we propose a two-stage framework to improve automatic ICD coding by capturing the label correlation. Specifically, we train a label set distribution estimator to rescore the probability of each label set candidate generated by a base predictor. This paper is the first attempt at learning the label set distribution as a reranking module for medical code prediction. In the experiments, our proposed framework is able to improve upon best-performing predictors on the benchmark MIMIC datasets. The source code of this project is available at https://github.com/MiuLab/ICD-Correlation.
xSense: Learning Sense-Separated Sparse Representations and Textual Definitions for Explainable Word Sense Networks
Sep 10, 2018
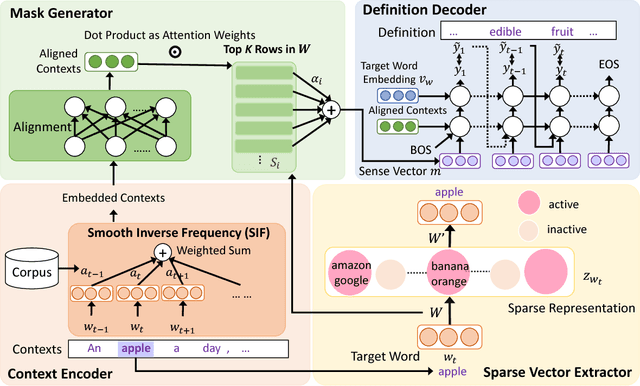
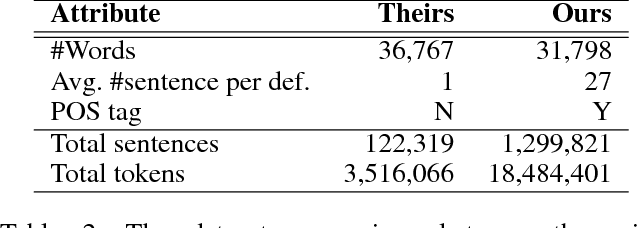
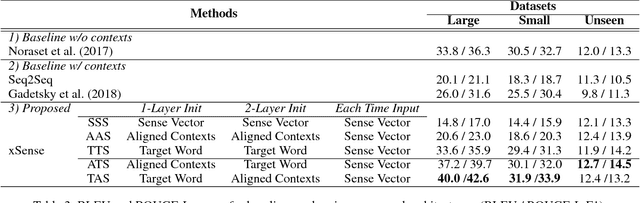
Despite the success achieved on various natural language processing tasks, word embeddings are difficult to interpret due to the dense vector representations. This paper focuses on interpreting the embeddings for various aspects, including sense separation in the vector dimensions and definition generation. Specifically, given a context together with a target word, our algorithm first projects the target word embedding to a high-dimensional sparse vector and picks the specific dimensions that can best explain the semantic meaning of the target word by the encoded contextual information, where the sense of the target word can be indirectly inferred. Finally, our algorithm applies an RNN to generate the textual definition of the target word in the human readable form, which enables direct interpretation of the corresponding word embedding. This paper also introduces a large and high-quality context-definition dataset that consists of sense definitions together with multiple example sentences per polysemous word, which is a valuable resource for definition modeling and word sense disambiguation. The conducted experiments show the superior performance in BLEU score and the human evaluation test.