 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkGuard: Deliberative Slow Thinking Leads to Cautious Guardrails
Feb 19, 2025Ensuring the safety of large language models (LLMs) is critical as they are deployed in real-world applications. Existing guardrails rely on rule-based filtering or single-pass classification, limiting their ability to handle nuanced safety violations. To address this, we propose ThinkGuard, a critique-augmented guardrail model that distills knowledge from high-capacity LLMs by generating structured critiques alongside safety labels. Fine-tuned on critique-augmented data, the captured deliberative thinking ability drastically enhances the guardrail's cautiousness and interpretability. Evaluated on multiple safety benchmarks, ThinkGuard achieves the highest average F1 and AUPRC, outperforming all baselines. Compared to LLaMA Guard 3, ThinkGuard improves accuracy by 16.1% and macro F1 by 27.0%. Moreover, it surpasses label-only fine-tuned models, confirming that structured critiques enhance both classification precision and nuanced safety reasoning while maintaining computational efficiency.
Rethinking Backdoor Detection Evaluation for Language Models
Aug 31, 2024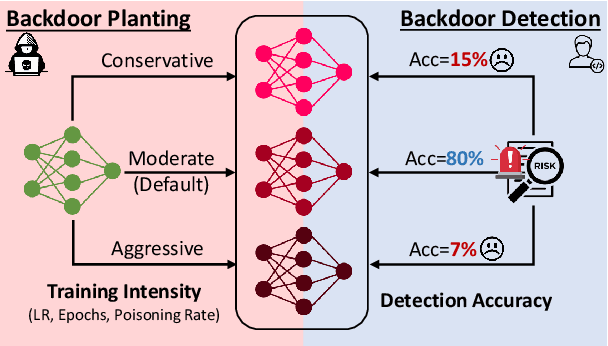



Backdoor attacks, in which a model behaves maliciously when given an attacker-specified trigger, pose a major security risk for practitioners who depend on publicly released language models. Backdoor detection methods aim to detect whether a released model contains a backdoor, so that practitioners can avoid such vulnerabilities. While existing backdoor detection methods have high accuracy in detecting backdoored models on standard benchmarks, it is unclear whether they can robustly identify backdoors in the wild. In this paper, we examine the robustness of backdoor detectors by manipulating different factors during backdoor planting. We find that the success of existing methods highly depends on how intensely the model is trained on poisoned data during backdoor planting. Specifically, backdoors planted with either more aggressive or more conservative training are significantly more difficult to detect than the default ones. Our results highlight a lack of robustness of existing backdoor detectors and the limitations in current benchmark construction.
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Jun 13, 2024



We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.