 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Backdoor Detection Evaluation for Language Models
Paper and Code
Aug 31, 2024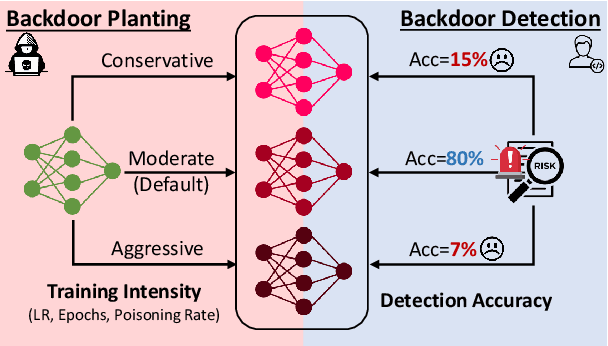



Backdoor attacks, in which a model behaves maliciously when given an attacker-specified trigger, pose a major security risk for practitioners who depend on publicly released language models. Backdoor detection methods aim to detect whether a released model contains a backdoor, so that practitioners can avoid such vulnerabilities. While existing backdoor detection methods have high accuracy in detecting backdoored models on standard benchmarks, it is unclear whether they can robustly identify backdoors in the wild. In this paper, we examine the robustness of backdoor detectors by manipulating different factors during backdoor planting. We find that the success of existing methods highly depends on how intensely the model is trained on poisoned data during backdoor planting. Specifically, backdoors planted with either more aggressive or more conservative training are significantly more difficult to detect than the default ones. Our results highlight a lack of robustness of existing backdoor detectors and the limitations in current benchmark construction.