 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Multi-Document Event Summarization: Evaluating Compression vs. Full-Text Approaches
Paper and Code
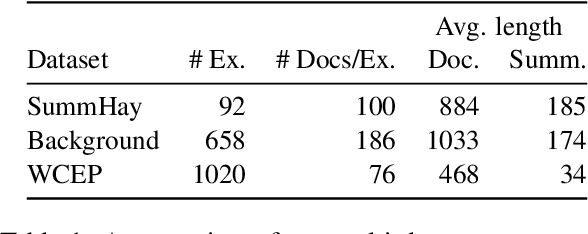



Automatically summarizing large text collections is a valuable tool for document research, with applications in journalism, academic research, legal work, and many other fields. In this work, we contrast two classes of systems for large-scale multi-document summarization (MDS): compression and full-text. Compression-based methods use a multi-stage pipeline and often lead to lossy summaries. Full-text methods promise a lossless summary by relying on recent advances in long-context reasoning. To understand their utility on large-scale MDS, we evaluated them on three datasets, each containing approximately one hundred documents per summary. Our experiments cover a diverse set of long-context transformers (Llama-3.1, Command-R, Jamba-1.5-Mini) and compression methods (retrieval-augmented, hierarchical, incremental). Overall, we find that full-text and retrieval methods perform the best in most settings. With further analysis into the salient information retention patterns, we show that compression-based methods show strong promise at intermediate stages, even outperforming full-context. However, they suffer information loss due to their multi-stage pipeline and lack of global context. Our results highlight the need to develop hybrid approaches that combine compression and full-text approaches for optimal performance on large-scale multi-document summarization.