 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks with Layer Reuse
Feb 01, 2019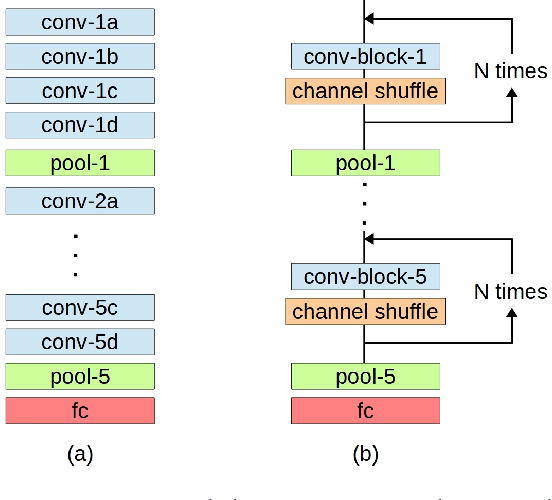


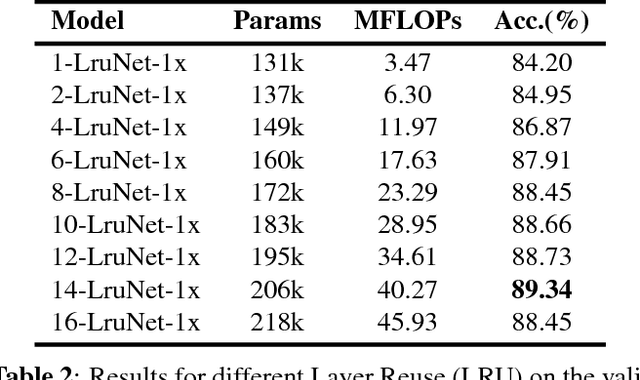
A convolutional layer in a Convolutional Neural Network (CNN) consists of many filters which apply convolution operation to the input, capture some special patterns and pass the result to the next layer. If the same patterns also occur at the deeper layers of the network, why wouldn't the same convolutional filters be used also in those layers? In this paper, we propose a CNN architecture, Layer Reuse Network (LruNet), where the convolutional layers are used repeatedly without the need of introducing new layers to get a better performance. This approach introduces several advantages: (i) Considerable amount of parameters are saved since we are reusing the layers instead of introducing new layers, (ii) the Memory Access Cost (MAC) can be reduced since reused layer parameters can be fetched only once, (iii) the number of nonlinearities increases with layer reuse, and (iv) reused layers get gradient updates from multiple parts of the network. The proposed approach is evaluated on CIFAR-10, CIFAR-100 and Fashion-MNIST datasets for image classification task, and layer reuse improves the performance by 5.14%, 5.85% and 2.29%, respectively. The source code and pretrained models are publicly available.
Multiple People Tracking Using Hierarchical Deep Tracklet Re-identification
Nov 17, 2018
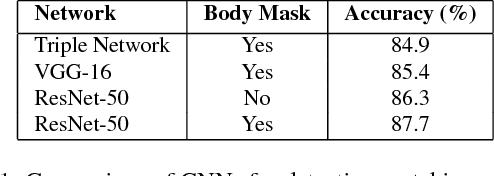
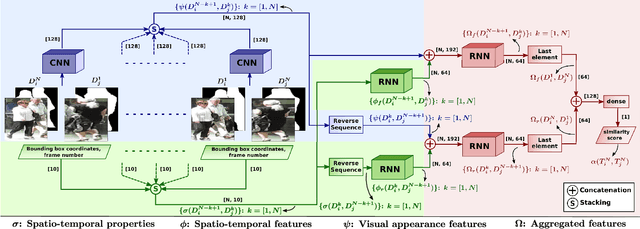

The task of multiple people tracking in monocular videos is challenging because of the numerous difficulties involved: occlusions, varying environments, crowded scenes, camera parameters and motion. In the tracking-by-detection paradigm, most approaches adopt person re-identification techniques based on computing the pairwise similarity between detections. However, these techniques are less effective in handling long-term occlusions. By contrast, tracklet (a sequence of detections) re-identification can improve association accuracy since tracklets offer a richer set of visual appearance and spatio-temporal cues. In this paper, we propose a tracking framework that employs a hierarchical clustering mechanism for merging tracklets. To this end, tracklet re-identification is performed by utilizing a novel multi-stage deep network that can jointly reason about the visual appearance and spatio-temporal properties of a pair of tracklets, thereby providing a robust measure of affinity. Experimental results on the challenging MOT16 and MOT17 benchmarks show that our method significantly outperforms state-of-the-arts.
Person Identification from Partial Gait Cycle Using Fully Convolutional Neural Network
Apr 23, 2018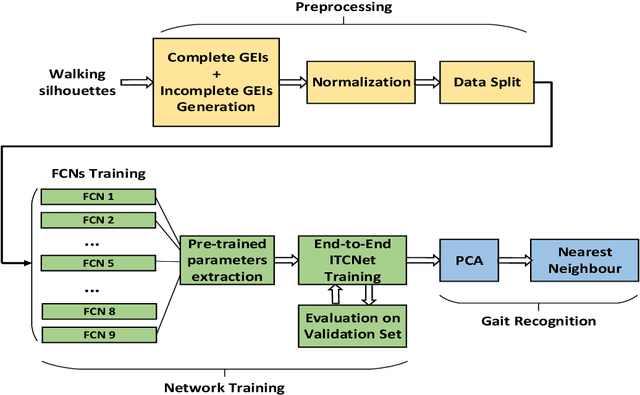
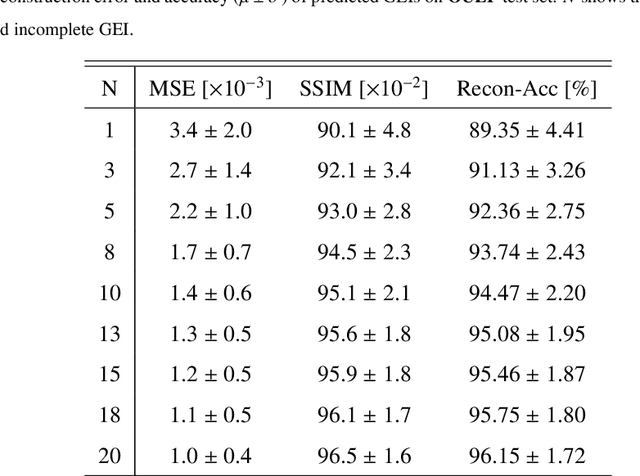
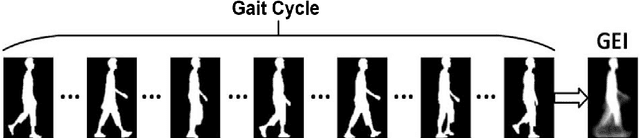
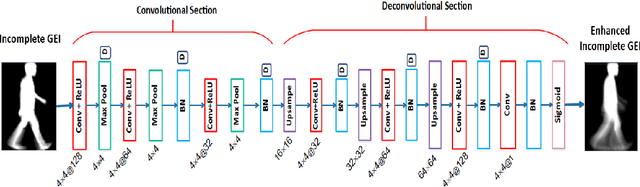
Gait as a biometric property for person identification plays a key role in video surveillance and security applications. In gait recognition, normally, gait feature such as Gait Energy Image (GEI) is extracted from one full gait cycle. However in many circumstances, such a full gait cycle might not be available due to occlusion. Thus, the GEI is not complete giving rise to a degrading in gait-based person identification rate. In this paper, we address this issue by proposing a novel method to identify individuals from gait feature when a few (or even single) frame(s) is available. To do so, we propose a deep learning-based approach to transform incomplete GEI to the corresponding complete GEI obtained from a full gait cycle. More precisely, this transformation is done gradually by training several auto encoders independently and then combining these as a uniform model. Experimental results on two public gait datasets, namely OULP and Casia-B demonstrate the validity of the proposed method in dealing with very incomplete gait cycles.