Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning as a Defense: Reducing Memorization in Large Language Models
Paper and Code
Feb 18, 2025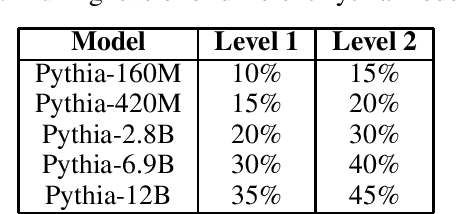
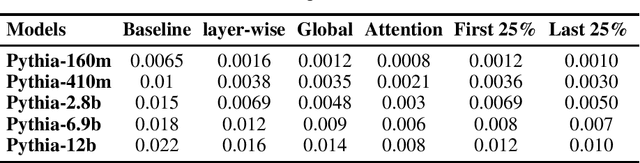
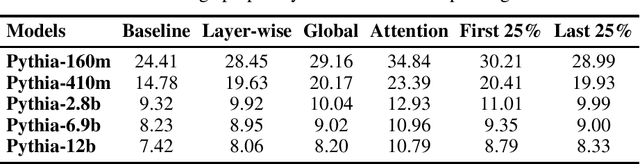
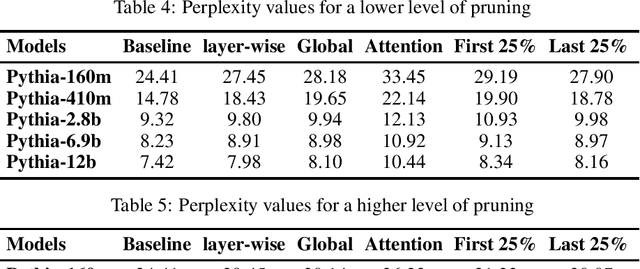
Large language models have been shown to memorize significant portions of their training data, which they can reproduce when appropriately prompted. This work investigates the impact of simple pruning techniques on this behavior. Our findings reveal that pruning effectively reduces the extent of memorization in LLMs, demonstrating its potential as a foundational approach for mitigating membership inference attacks.
View paper on