 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Computing Class-wise Universal Adversarial Perturbations
Paper and Code
Dec 01, 2019
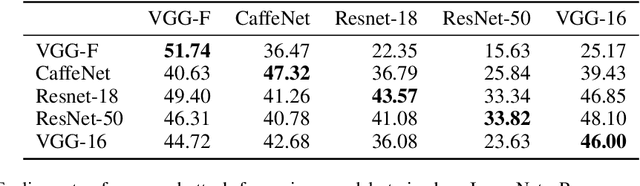


We present an algorithm for computing class-specific universal adversarial perturbations for deep neural networks. Such perturbations can induce misclassification in a large fraction of images of a specific class. Unlike previous methods that use iterative optimization for computing a universal perturbation, the proposed method employs a perturbation that is a linear function of weights of the neural network and hence can be computed much faster. The method does not require any training data and has no hyper-parameters. The attack obtains 34% to 51% fooling rate on state-of-the-art deep neural networks on ImageNet and transfers across models. We also study the characteristics of the decision boundaries learned by standard and adversarially trained models to understand the universal adversarial perturbations.