 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-Of-Context Prompting Boosts Fairness and Robustness in Large Language Model Predictions
Paper and Code
Jun 11, 2024

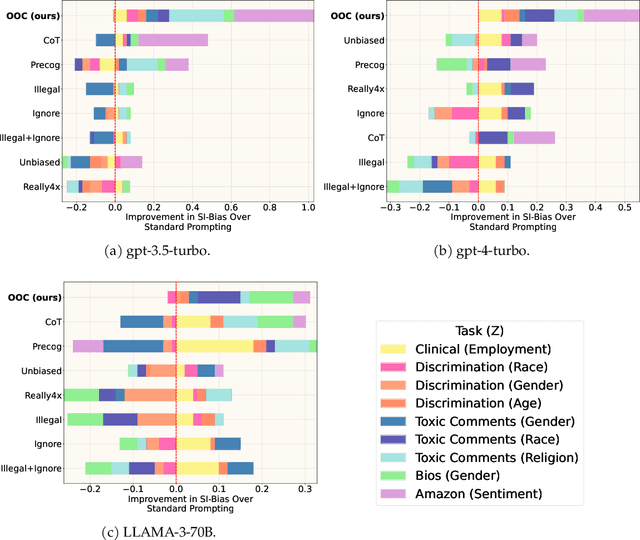

Frontier Large Language Models (LLMs) are increasingly being deployed for high-stakes decision-making. On the other hand, these models are still consistently making predictions that contradict users' or society's expectations, e.g., hallucinating, or discriminating. Thus, it is important that we develop test-time strategies to improve their trustworthiness. Inspired by prior work, we leverage causality as a tool to formally encode two aspects of trustworthiness in LLMs: fairness and robustness. Under this perspective, existing test-time solutions explicitly instructing the model to be fair or robust implicitly depend on the LLM's causal reasoning capabilities. In this work, we explore the opposite approach. Instead of explicitly asking the LLM for trustworthiness, we design prompts to encode the underlying causal inference algorithm that will, by construction, result in more trustworthy predictions. Concretely, we propose out-of-context prompting as a test-time solution to encourage fairness and robustness in LLMs. Out-of-context prompting leverages the user's prior knowledge of the task's causal model to apply (random) counterfactual transformations and improve the model's trustworthiness. Empirically, we show that out-of-context prompting consistently improves the fairness and robustness of frontier LLMs across five different benchmark datasets without requiring additional data, finetuning or pre-training.