 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Object Pose Recovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
Paper and Code
Jan 28, 2020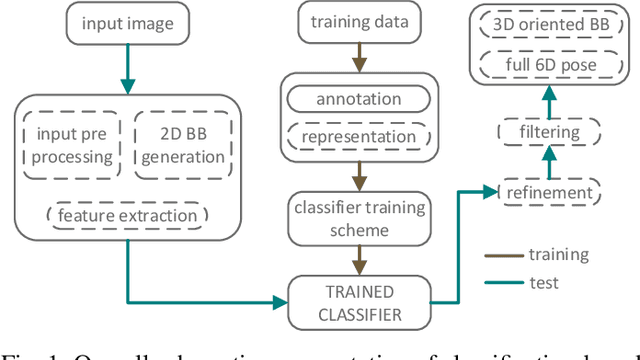
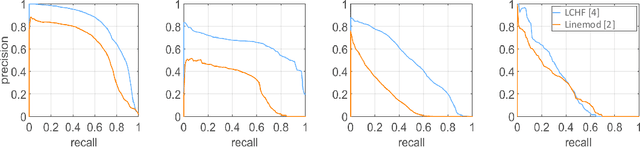
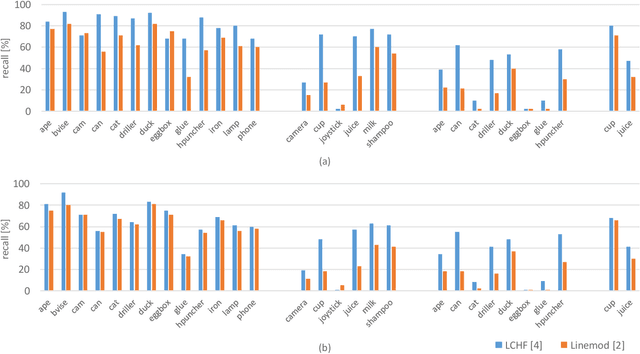
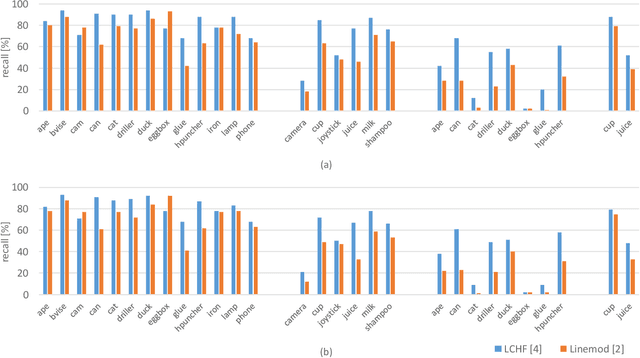
Object pose recovery has gained increasing attention in the computer vision field as it has become an important problem in rapidly evolving technological areas related to autonomous driving, robotics, and augmented reality. Existing review-related studies have addressed the problem at visual level in 2D, going through the methods which produce 2D bounding boxes of objects of interest in RGB images. The 2D search space is enlarged either using the geometry information available in the 3D space along with RGB (Mono/Stereo) images, or utilizing depth data from LIDAR sensors and/or RGB-D cameras. 3D bounding box detectors, producing category-level amodal 3D bounding boxes, are evaluated on gravity aligned images, while full 6D object pose estimators are mostly tested at instance-level on the images where the alignment constraint is removed. Recently, 6D object pose estimation is tackled at the level of categories. In this paper, we present the first comprehensive and most recent review of the methods on object pose recovery, from 3D bounding box detectors to full 6D pose estimators. The methods mathematically model the problem as a classification, regression, classification & regression, template matching, and point-pair feature matching task. Based on this, a mathematical-model-based categorization of the methods is established. Datasets used for evaluating the methods are investigated with respect to the challenges, and evaluation metrics are studied. Quantitative results of experiments in the literature are analysed to show which category of methods best performs across what types of challenges. The analyses are further extended comparing two methods, which are our own implementations, so that the outcomes from the public results are further solidified. Current position of the field is summarized regarding object pose recovery, and possible research directions are identified.