 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Object Pose Recovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
Jan 28, 2020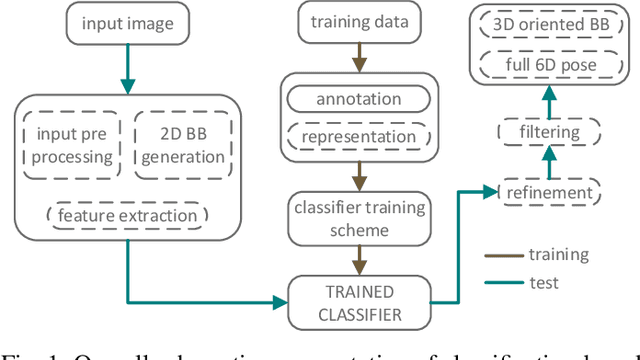
Object pose recovery has gained increasing attention in the computer vision field as it has become an important problem in rapidly evolving technological areas related to autonomous driving, robotics, and augmented reality. Existing review-related studies have addressed the problem at visual level in 2D, going through the methods which produce 2D bounding boxes of objects of interest in RGB images. The 2D search space is enlarged either using the geometry information available in the 3D space along with RGB (Mono/Stereo) images, or utilizing depth data from LIDAR sensors and/or RGB-D cameras. 3D bounding box detectors, producing category-level amodal 3D bounding boxes, are evaluated on gravity aligned images, while full 6D object pose estimators are mostly tested at instance-level on the images where the alignment constraint is removed. Recently, 6D object pose estimation is tackled at the level of categories. In this paper, we present the first comprehensive and most recent review of the methods on object pose recovery, from 3D bounding box detectors to full 6D pose estimators. The methods mathematically model the problem as a classification, regression, classification & regression, template matching, and point-pair feature matching task. Based on this, a mathematical-model-based categorization of the methods is established. Datasets used for evaluating the methods are investigated with respect to the challenges, and evaluation metrics are studied. Quantitative results of experiments in the literature are analysed to show which category of methods best performs across what types of challenges. The analyses are further extended comparing two methods, which are our own implementations, so that the outcomes from the public results are further solidified. Current position of the field is summarized regarding object pose recovery, and possible research directions are identified.
Instance- and Category-level 6D Object Pose Estimation
Mar 11, 2019

6D object pose estimation is an important task that determines the 3D position and 3D rotation of an object in camera-centred coordinates. By utilizing such a task, one can propose promising solutions for various problems related to scene understanding, augmented reality, control and navigation of robotics. Recent developments on visual depth sensors and low-cost availability of depth data significantly facilitate object pose estimation. Using depth information from RGB-D sensors, substantial progress has been made in the last decade by the methods addressing the challenges such as viewpoint variability, occlusion and clutter, and similar looking distractors. Particularly, with the recent advent of convolutional neural networks, RGB-only based solutions have been presented. However, improved results have only been reported for recovering the pose of known instances, i.e., for the instance-level object pose estimation tasks. More recently, state-of-the-art approaches target to solve object pose estimation problem at the level of categories, recovering the 6D pose of unknown instances. To this end, they address the challenges of the category-level tasks such as distribution shift among source and target domains, high intra-class variations, and shape discrepancies between objects.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
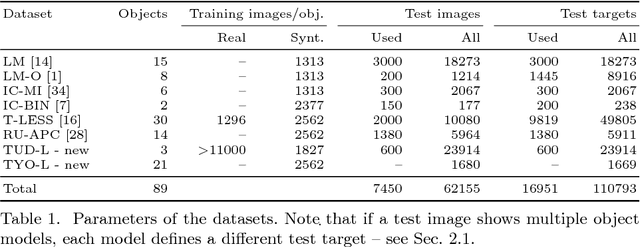

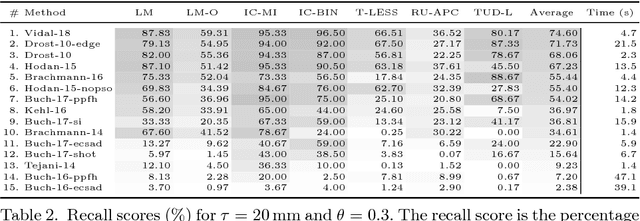
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Recovering 6D Object Pose: A Review and Multi-modal Analysis
Aug 15, 2018

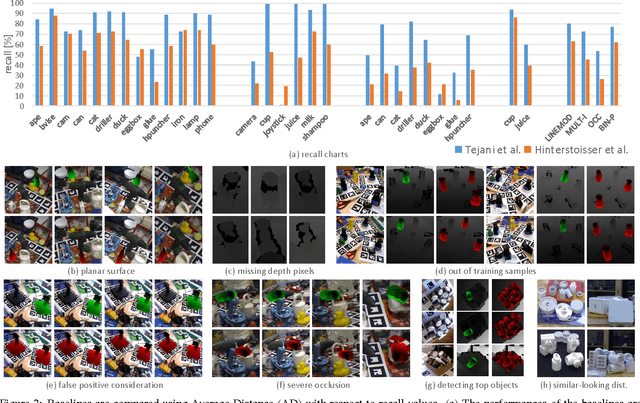
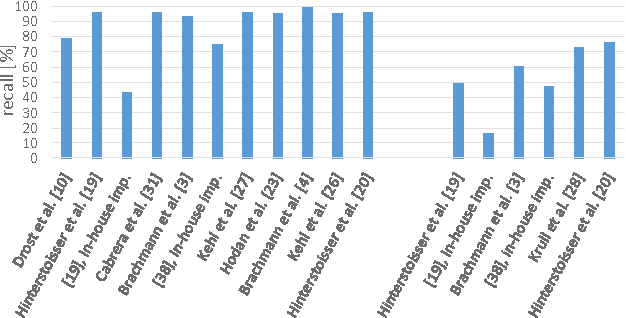
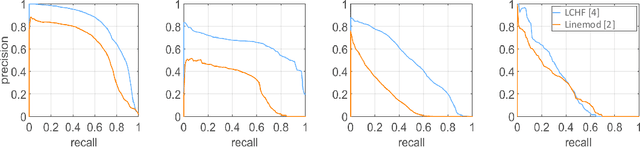
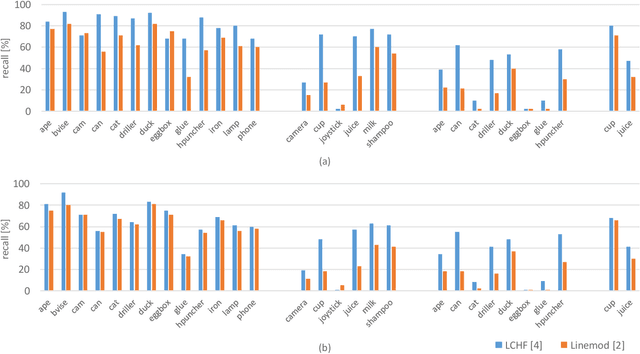
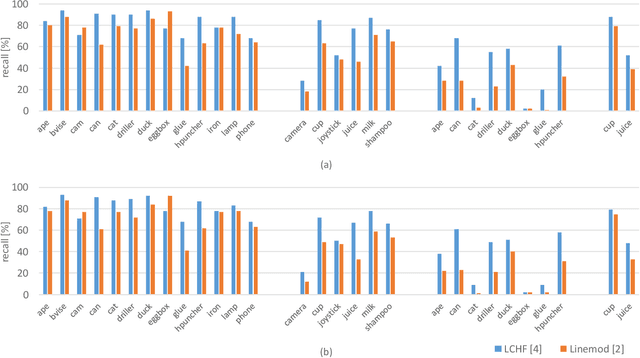
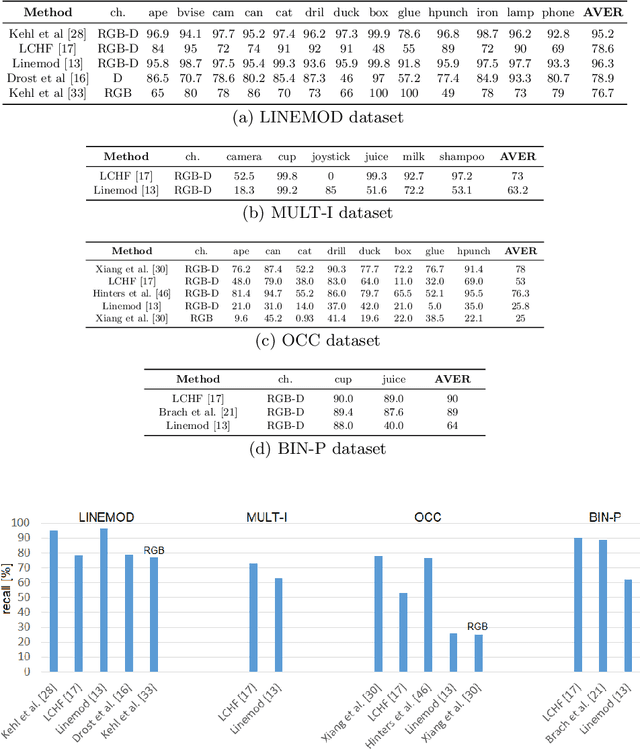
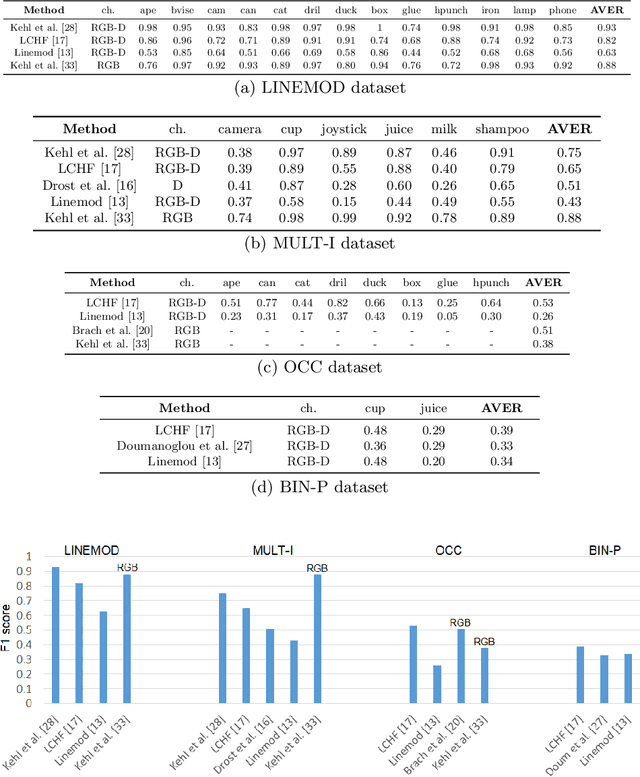
A large number of studies analyse object detection and pose estimation at visual level in 2D, discussing the effects of challenges such as occlusion, clutter, texture, etc., on the performances of the methods, which work in the context of RGB modality. Interpreting the depth data, the study in this paper presents thorough multi-modal analyses. It discusses the above-mentioned challenges for full 6D object pose estimation in RGB-D images comparing the performances of several 6D detectors in order to answer the following questions: What is the current position of the computer vision community for maintaining "automation" in robotic manipulation? What next steps should the community take for improving "autonomy" in robotics while handling objects? Our findings include: (i) reasonably accurate results are obtained on textured-objects at varying viewpoints with cluttered backgrounds. (ii) Heavy existence of occlusion and clutter severely affects the detectors, and similar-looking distractors is the biggest challenge in recovering instances' 6D. (iii) Template-based methods and random forest-based learning algorithms underlie object detection and 6D pose estimation. Recent paradigm is to learn deep discriminative feature representations and to adopt CNNs taking RGB images as input. (iv) Depending on the availability of large-scale 6D annotated depth datasets, feature representations can be learnt on these datasets, and then the learnt representations can be customized for the 6D problem.
Category-level 6D Object Pose Recovery in Depth Images
Aug 01, 2018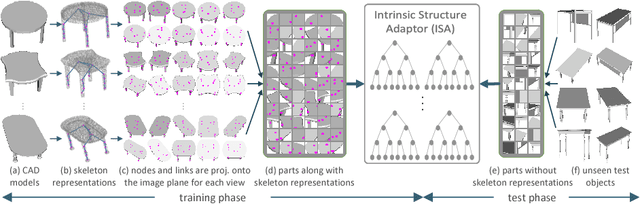
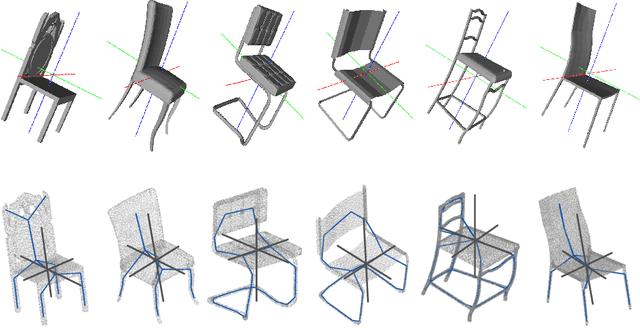
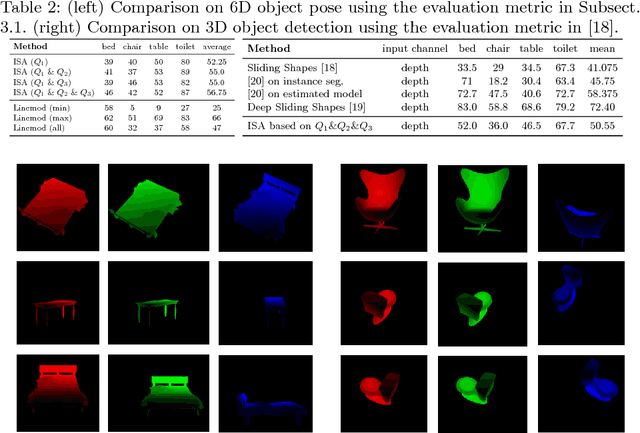
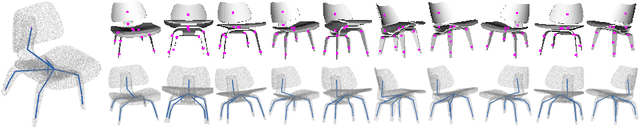
Intra-class variations, distribution shifts among source and target domains are the major challenges of category-level tasks. In this study, we address category-level full 6D object pose estimation in the context of depth modality, introducing a novel part-based architecture that can tackle the above-mentioned challenges. Our architecture particularly adapts the distribution shifts arising from shape discrepancies, and naturally removes the variations of texture, illumination, pose, etc., so we call it as "Intrinsic Structure Adaptor (ISA)". We engineer ISA based on the followings: i) "Semantically Selected Centers (SSC)" are proposed in order to define the "6D pose" at the level of categories. ii) 3D skeleton structures, which we derive as shape-invariant features, are used to represent the parts extracted from the instances of given categories, and privileged one-class learning is employed based on these parts. iii) Graph matching is performed during training in such a way that the adaptation/generalization capability of the proposed architecture is improved across unseen instances. Experiments validate the promising performance of the proposed architecture on both synthetic and real datasets.
Multi-Task Deep Networks for Depth-Based 6D Object Pose and Joint Registration in Crowd Scenarios
Jun 11, 2018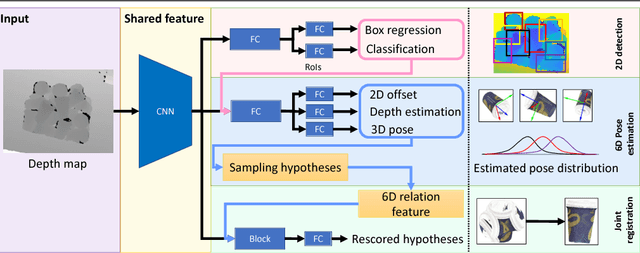


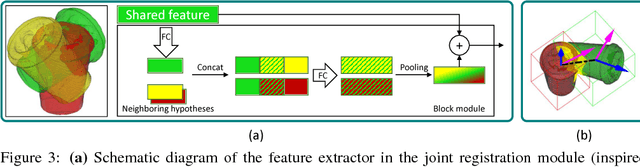
In bin-picking scenarios, multiple instances of an object of interest are stacked in a pile randomly, and hence, the instances are inherently subjected to the challenges: severe occlusion, clutter, and similar-looking distractors. Most existing methods are, however, for single isolated object instances, while some recent methods tackle crowd scenarios as post-refinement which accounts multiple object relations. In this paper, we address recovering 6D poses of multiple instances in bin-picking scenarios in depth modality by multi-task learning in deep neural networks. Our architecture jointly learns multiple sub-tasks: 2D detection, depth, and 3D pose estimation of individual objects; and joint registration of multiple objects. For training data generation, depth images of physically plausible object pose configurations are generated by a 3D object model in a physics simulation, which yields diverse occlusion patterns to learn. We adopt a state-of-the-art object detector, and 2D offsets are further estimated via a network to refine misaligned 2D detections. The depth and 3D pose estimator is designed to generate multiple hypotheses per detection. This allows the joint registration network to learn occlusion patterns and remove physically implausible pose hypotheses. We apply our architecture on both synthetic (our own and Sileane dataset) and real (a public Bin-Picking dataset) data, showing that it significantly outperforms state-of-the-art methods by 15-31% in average precision.
A Learning-based Variable Size Part Extraction Architecture for 6D Object Pose Recovery in Depth
Jan 09, 2017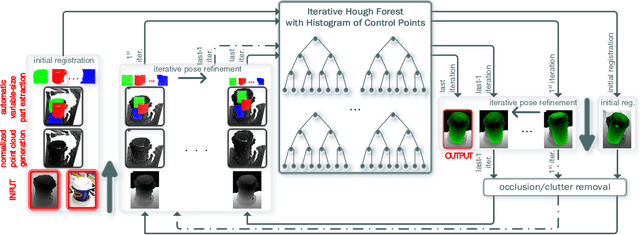
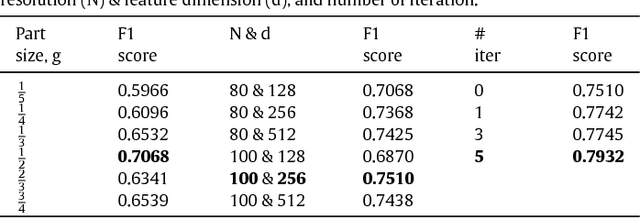
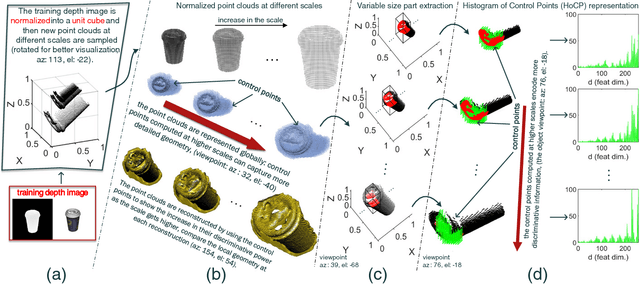
State-of-the-art techniques for 6D object pose recovery depend on occlusion-free point clouds to accurately register objects in 3D space. To deal with this shortcoming, we introduce a novel architecture called Iterative Hough Forest with Histogram of Control Points that is capable of estimating the 6D pose of occluded and cluttered objects given a candidate 2D bounding box. Our Iterative Hough Forest (IHF) is learnt using parts extracted only from the positive samples. These parts are represented with Histogram of Control Points (HoCP), a "scale-variant" implicit volumetric description, which we derive from recently introduced Implicit B-Splines (IBS). The rich discriminative information provided by the scale-variant HoCP features is leveraged during inference. An automatic variable size part extraction framework iteratively refines the object's initial pose that is roughly aligned due to the extraction of coarsest parts, the ones occupying the largest area in image pixels. The iterative refinement is accomplished based on finer (smaller) parts that are represented with more discriminative control point descriptors by using our Iterative Hough Forest. Experiments conducted on a publicly available dataset report that our approach show better registration performance than the state-of-the-art methods.
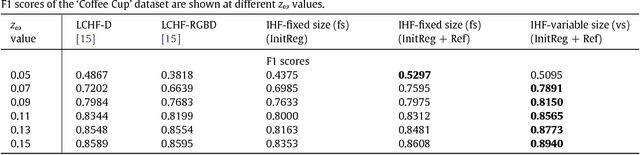
Iterative Hough Forest with Histogram of Control Points for 6 DoF Object Registration from Depth Images
Jan 09, 2017
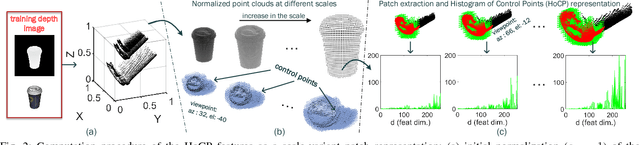
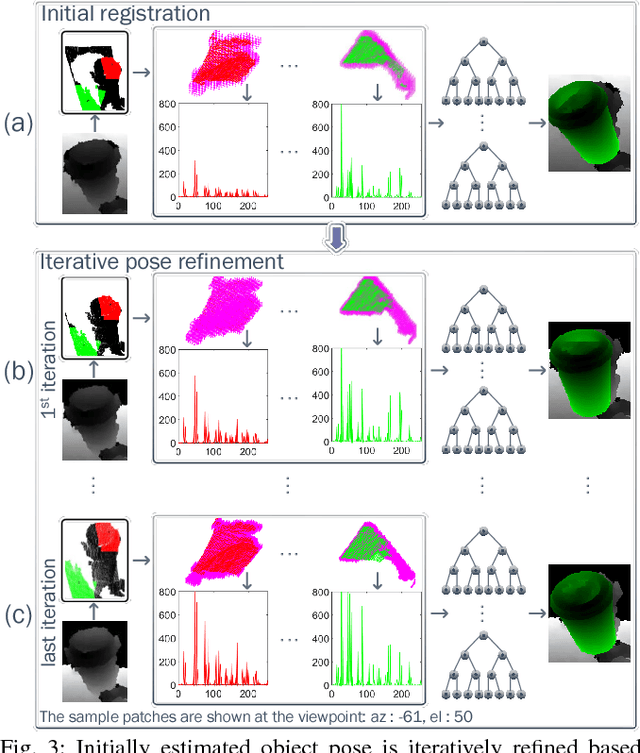
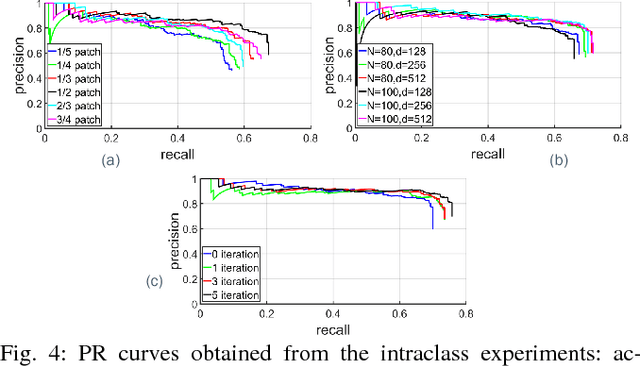
State-of-the-art techniques proposed for 6D object pose recovery depend on occlusion-free point clouds to accurately register objects in 3D space. To reduce this dependency, we introduce a novel architecture called Iterative Hough Forest with Histogram of Control Points that is capable of estimating occluded and cluttered objects' 6D pose given a candidate 2D bounding box. Our Iterative Hough Forest is learnt using patches extracted only from the positive samples. These patches are represented with Histogram of Control Points (HoCP), a "scale-variant" implicit volumetric description, which we derive from recently introduced Implicit B-Splines (IBS). The rich discriminative information provided by this scale-variance is leveraged during inference, where the initial pose estimation of the object is iteratively refined based on more discriminative control points by using our Iterative Hough Forest. We conduct experiments on several test objects of a publicly available dataset to test our architecture and to compare with the state-of-the-art.