 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive 6D Multi-Object Pose Estimation in Cluttered Scenarios with Deep Reinforcement Learning
Paper and Code
Oct 19, 2019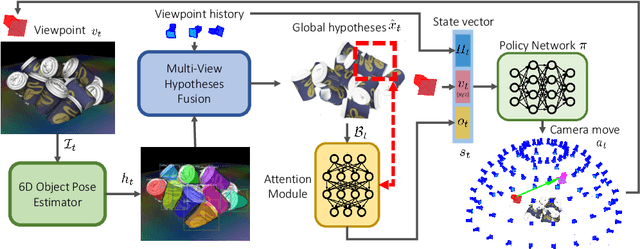
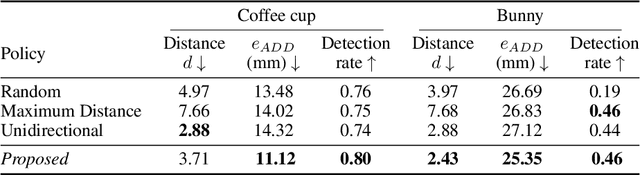
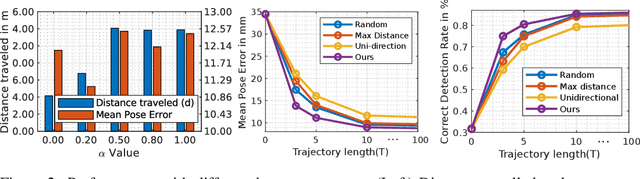

In this work, we explore how a strategic selection of camera movements can facilitate the task of 6D multi-object pose estimation in cluttered scenarios while respecting real-world constraints important in robotics and augmented reality applications, such as time and distance traveled. In the proposed framework, a set of multiple object hypotheses is given to an agent, which is inferred by an object pose estimator and subsequently spatio-temporally selected by a fusion function that makes use of a verification score that circumvents the need of ground-truth annotations. The agent reasons about these hypotheses, directing its attention to the object which it is most uncertain about, moving the camera towards such an object. Unlike previous works that propose short-sighted policies, our agent is trained in simulated scenarios using reinforcement learning, attempting to learn the camera moves that produce the most accurate object poses hypotheses for a given temporal and spatial budget, without the need of viewpoints rendering during inference. Our experiments show that the proposed approach successfully estimates the 6D object pose of a stack of objects in both challenging cluttered synthetic and real scenarios, showing superior performance compared to strong baselines.