 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Based Dexterous Manipulations with Estimated Hand Poses and Residual Reinforcement Learning
Paper and Code
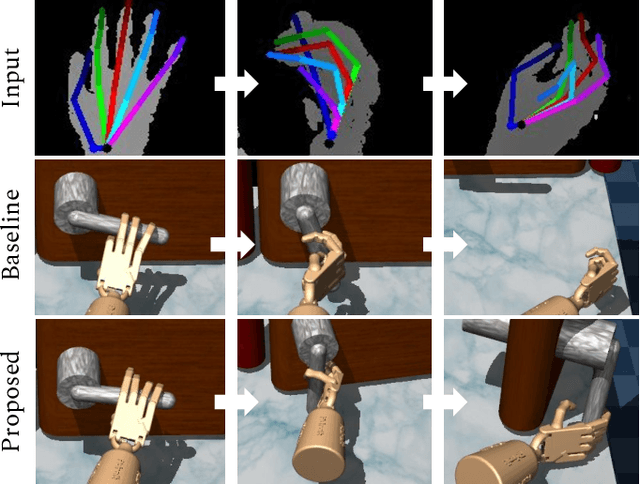
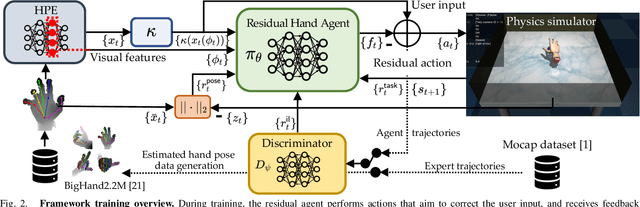
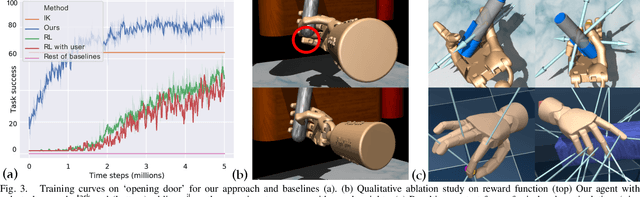
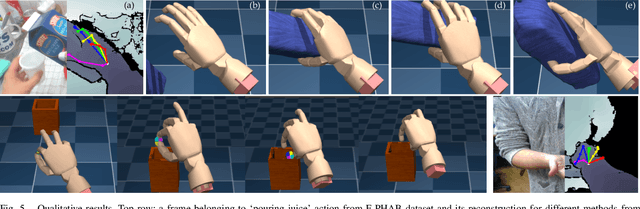
Dexterous manipulation of objects in virtual environments with our bare hands, by using only a depth sensor and a state-of-the-art 3D hand pose estimator (HPE), is challenging. While virtual environments are ruled by physics, e.g. object weights and surface frictions, the absence of force feedback makes the task challenging, as even slight inaccuracies on finger tips or contact points from HPE may make the interactions fail. Prior arts simply generate contact forces in the direction of the fingers' closures, when finger joints penetrate virtual objects. Although useful for simple grasping scenarios, they cannot be applied to dexterous manipulations such as in-hand manipulation. Existing reinforcement learning (RL) and imitation learning (IL) approaches train agents that learn skills by using task-specific rewards, without considering any online user input. In this work, we propose to learn a model that maps noisy input hand poses to target virtual poses, which introduces the needed contacts to accomplish the tasks on a physics simulator. The agent is trained in a residual setting by using a model-free hybrid RL+IL approach. A 3D hand pose estimation reward is introduced leading to an improvement on HPE accuracy when the physics-guided corrected target poses are remapped to the input space. As the model corrects HPE errors by applying minor but crucial joint displacements for contacts, this helps to keep the generated motion visually close to the user input. Since HPE sequences performing successful virtual interactions do not exist, a data generation scheme to train and evaluate the system is proposed. We test our framework in two applications that use hand pose estimates for dexterous manipulations: hand-object interactions in VR and hand-object motion reconstruction in-the-wild.