 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning
Paper and Code
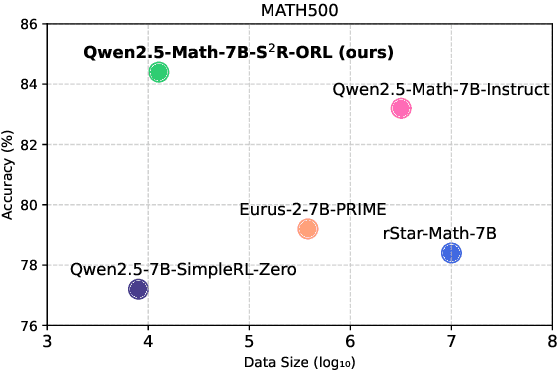
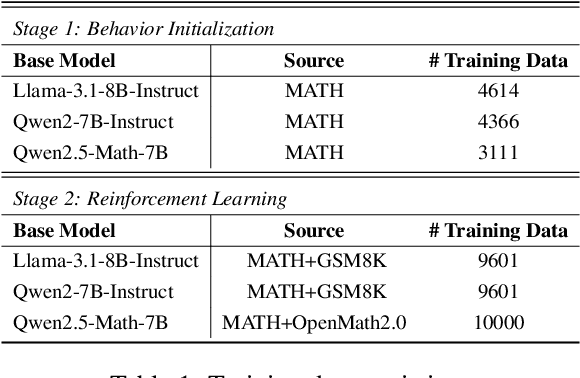
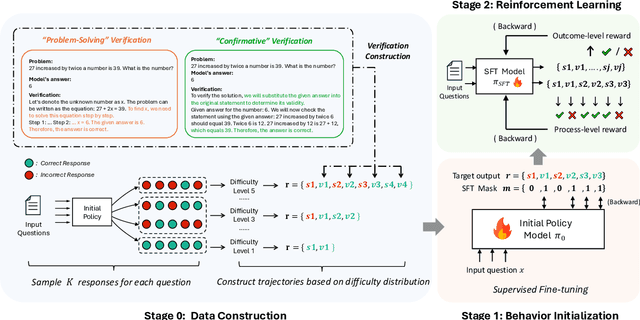
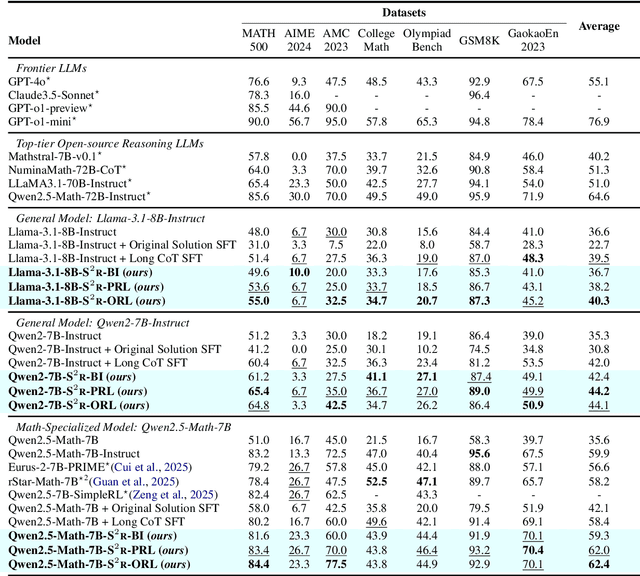
Recent studies have demonstrated the effectiveness of LLM test-time scaling. However, existing approaches to incentivize LLMs' deep thinking abilities generally require large-scale data or significant training efforts. Meanwhile, it remains unclear how to improve the thinking abilities of less powerful base models. In this work, we introduce S$^2$R, an efficient framework that enhances LLM reasoning by teaching models to self-verify and self-correct during inference. Specifically, we first initialize LLMs with iterative self-verification and self-correction behaviors through supervised fine-tuning on carefully curated data. The self-verification and self-correction skills are then further strengthened by both outcome-level and process-level reinforcement learning, with minimized resource requirements, enabling the model to adaptively refine its reasoning process during inference. Our results demonstrate that, with only 3.1k self-verifying and self-correcting behavior initialization samples, Qwen2.5-math-7B achieves an accuracy improvement from 51.0\% to 81.6\%, outperforming models trained on an equivalent amount of long-CoT distilled data. Extensive experiments and analysis based on three base models across both in-domain and out-of-domain benchmarks validate the effectiveness of S$^2$R. Our code and data are available at https://github.com/NineAbyss/S2R.