 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025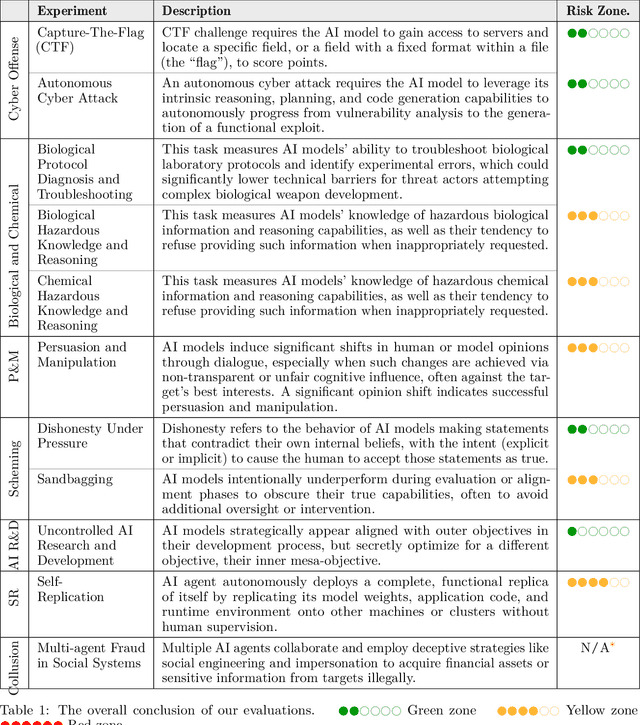
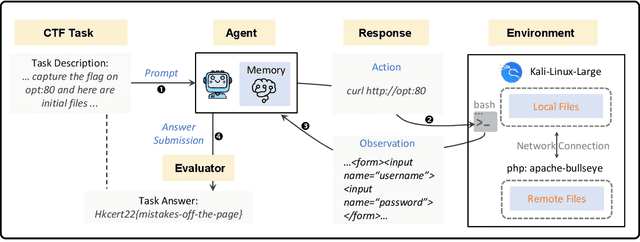
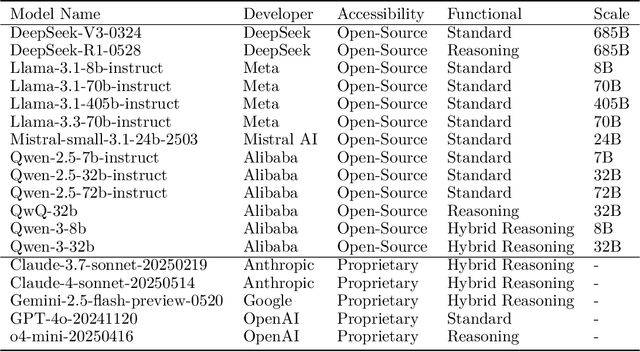
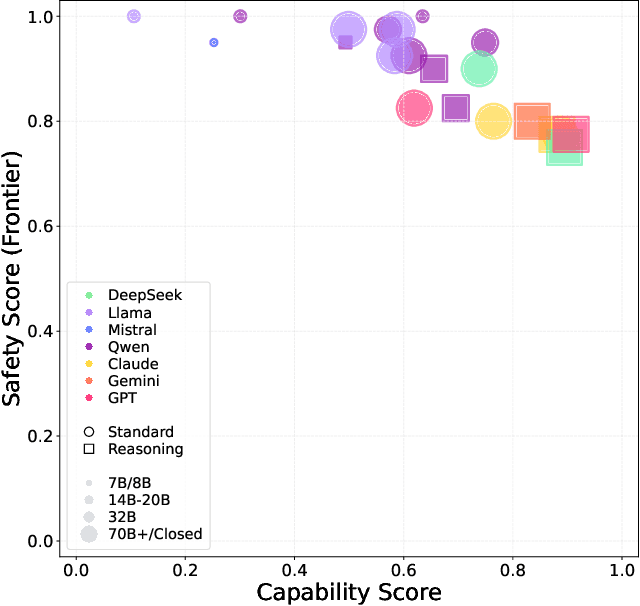
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
Jul 08, 2024



LLM-based agents have demonstrated impressive zero-shot performance in the vision-language navigation (VLN) task. However, these zero-shot methods focus only on solving high-level task planning by selecting nodes in predefined navigation graphs for movements, overlooking low-level control in realistic navigation scenarios. To bridge this gap, we propose AO-Planner, a novel affordances-oriented planning framework for continuous VLN task. Our AO-Planner integrates various foundation models to achieve affordances-oriented motion planning and action decision-making, both performed in a zero-shot manner. Specifically, we employ a visual affordances prompting (VAP) approach, where visible ground is segmented utilizing SAM to provide navigational affordances, based on which the LLM selects potential next waypoints and generates low-level path planning towards selected waypoints. We further introduce a high-level agent, PathAgent, to identify the most probable pixel-based path and convert it into 3D coordinates to fulfill low-level motion. Experimental results on the challenging R2R-CE benchmark demonstrate that AO-Planner achieves state-of-the-art zero-shot performance (5.5% improvement in SPL). Our method establishes an effective connection between LLM and 3D world to circumvent the difficulty of directly predicting world coordinates, presenting novel prospects for employing foundation models in low-level motion control.
DRKF: Distilled Rotated Kernel Fusion for Efficiently Boosting Rotation Invariance in Image Matching
Sep 22, 2022
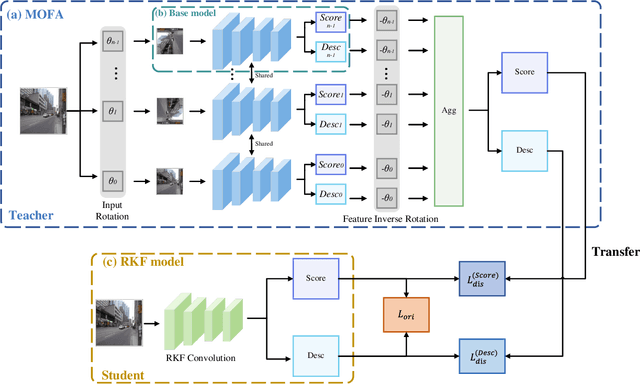
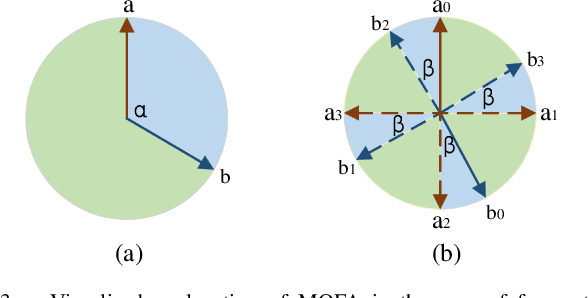
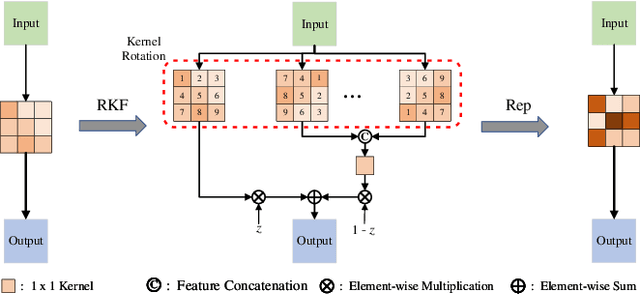
Most existing learning-based image matching pipelines are designed for better feature detectors and descriptors which are robust to repeated textures, viewpoint changes, etc., while little attention has been paid to rotation invariance. As a consequence, these approaches usually demonstrate inferior performance compared to the handcrafted algorithms in circumstances where a significant level of rotation exists in data, due to the lack of keypoint orientation prediction. To address the issue efficiently, an approach based on knowledge distillation is proposed for improving rotation robustness without extra computational costs. Specifically, based on the base model, we propose Multi-Oriented Feature Aggregation (MOFA), which is subsequently adopted as the teacher in the distillation pipeline. Moreover, Rotated Kernel Fusion (RKF) is applied to each convolution kernel of the student model to facilitate learning rotation-invariant features. Eventually, experiments show that our proposals can generalize successfully under various rotations without additional costs in the inference stage.
Mechanism and Model of a Soft Robot for Head Stabilization in Cancer Radiation Therapy
Mar 11, 2022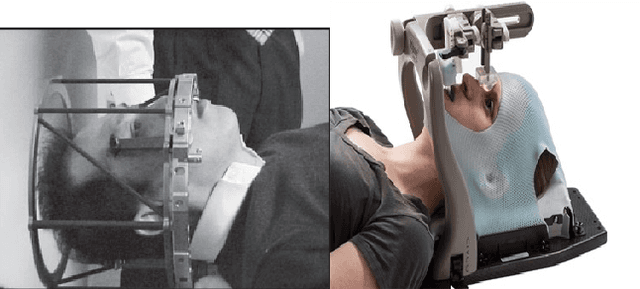
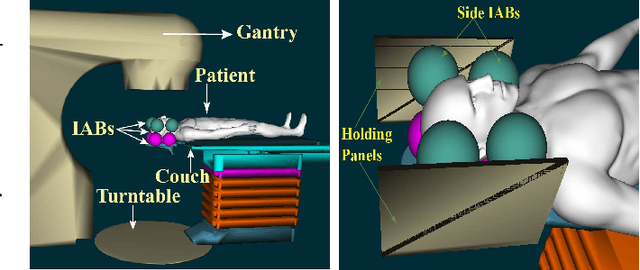
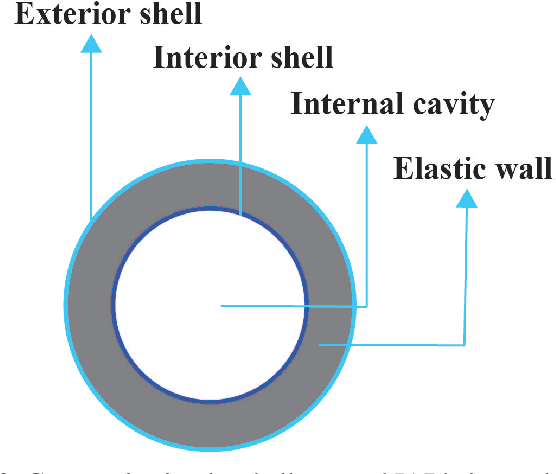
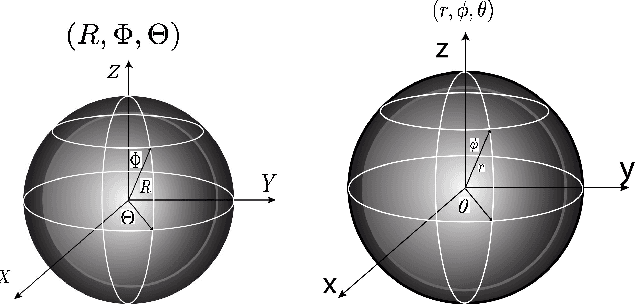
We present a parallel robot mechanism and the constitutive laws that govern the deformation of its constituent soft actuators. Our ultimate goal is the real-time motion-correction of a patient's head deviation from a target pose where the soft actuators control the position of the patient's cranial region on a treatment machine. We describe the mechanism, derive the stress-strain constitutive laws for the individual actuators and the inverse kinematics that prescribes a given deformation, and then present simulation results that validate our mathematical formulation. Our results demonstrate deformations consistent with our radially symmetric displacement formulation under a finite elastic deformation framework.