 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Language-Colored Pointmap Pretraining for Unified 3D Scene Understanding
Apr 02, 2026Pretraining 3D encoders by aligning with Contrastive Language Image Pretraining (CLIP) has emerged as a promising direction to learn generalizable representations for 3D scene understanding. In this paper, we propose UniScene3D, a transformer-based encoder that learns unified scene representations from multi-view colored pointmaps, jointly modeling image appearance and geometry. For robust colored pointmap representation learning, we introduce novel cross-view geometric alignment and grounded view alignment to enforce cross-view geometry and semantic consistency. Extensive low-shot and task-specific fine-tuning evaluations on viewpoint grounding, scene retrieval, scene type classification, and 3D VQA demonstrate our state-of-the-art performance. These results highlight the effectiveness of our approach for unified 3D scene understanding. https://yebulabula.github.io/UniScene3D/
From None to All: Self-Supervised 3D Reconstruction via Novel View Synthesis
Mar 29, 2026In this paper, we introduce NAS3R, a self-supervised feed-forward framework that jointly learns explicit 3D geometry and camera parameters with no ground-truth annotations and no pretrained priors. During training, NAS3R reconstructs 3D Gaussians from uncalibrated and unposed context views and renders target views using its self-predicted camera parameters, enabling self-supervised training from 2D photometric supervision. To ensure stable convergence, NAS3R integrates reconstruction and camera prediction within a shared transformer backbone regulated by masked attention, and adopts a depth-based Gaussian formulation that facilitates well-conditioned optimization. The framework is compatible with state-of-the-art supervised 3D reconstruction architectures and can incorporate pretrained priors or intrinsic information when available. Extensive experiments show that NAS3R achieves superior results to other self-supervised methods, establishing a scalable and geometry-aware paradigm for 3D reconstruction from unconstrained data. Code and models are publicly available at https://ranrhuang.github.io/nas3r/.
Cross-layer Attention Network for Fine-grained Visual Categorization
Oct 17, 2022
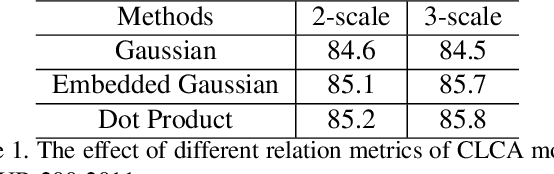
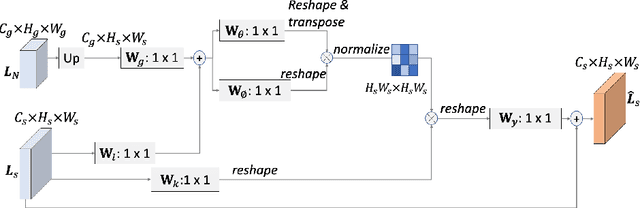
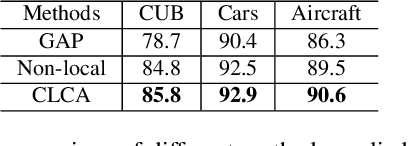
Learning discriminative representations for subtle localized details plays a significant role in Fine-grained Visual Categorization (FGVC). Compared to previous attention-based works, our work does not explicitly define or localize the part regions of interest; instead, we leverage the complementary properties of different stages of the network, and build a mutual refinement mechanism between the mid-level feature maps and the top-level feature map by our proposed Cross-layer Attention Network (CLAN). Specifically, CLAN is composed of 1) the Cross-layer Context Attention (CLCA) module, which enhances the global context information in the intermediate feature maps with the help of the top-level feature map, thereby improving the expressive power of the middle layers, and 2) the Cross-layer Spatial Attention (CLSA) module, which takes advantage of the local attention in the mid-level feature maps to boost the feature extraction of local regions at the top-level feature maps. Experimental results show our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft). Ablation studies and visualizations are provided to understand our approach. Experimental results show our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft).
DRKF: Distilled Rotated Kernel Fusion for Efficiently Boosting Rotation Invariance in Image Matching
Sep 22, 2022
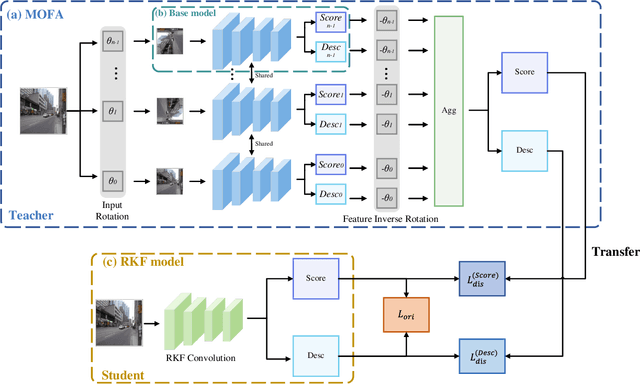
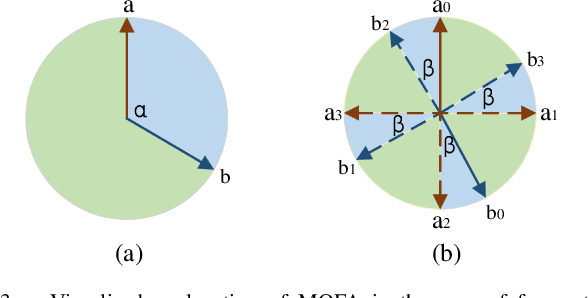
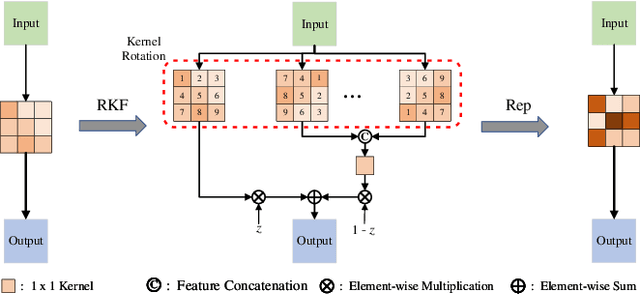
Most existing learning-based image matching pipelines are designed for better feature detectors and descriptors which are robust to repeated textures, viewpoint changes, etc., while little attention has been paid to rotation invariance. As a consequence, these approaches usually demonstrate inferior performance compared to the handcrafted algorithms in circumstances where a significant level of rotation exists in data, due to the lack of keypoint orientation prediction. To address the issue efficiently, an approach based on knowledge distillation is proposed for improving rotation robustness without extra computational costs. Specifically, based on the base model, we propose Multi-Oriented Feature Aggregation (MOFA), which is subsequently adopted as the teacher in the distillation pipeline. Moreover, Rotated Kernel Fusion (RKF) is applied to each convolution kernel of the student model to facilitate learning rotation-invariant features. Eventually, experiments show that our proposals can generalize successfully under various rotations without additional costs in the inference stage.
Physical Adversarial Attack on Vehicle Detector in the Carla Simulator
Aug 07, 2020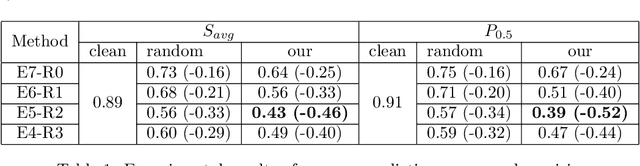
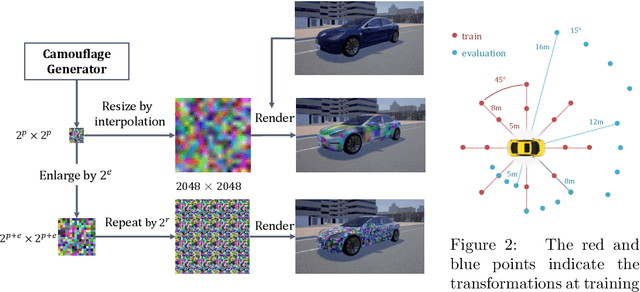
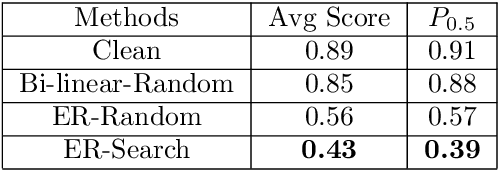
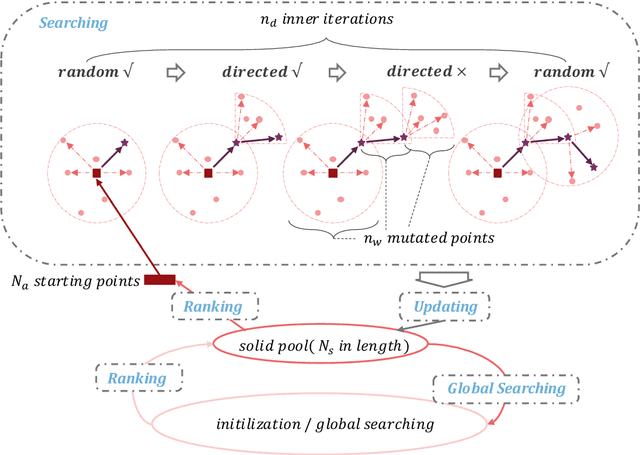
In this paper, we tackle the issue of physical adversarial examples for object detectors in the wild. Specifically, we proposed to generate adversarial patterns to be applied on vehicle surface so that it's not recognizable by detectors in the photo-realistic Carla simulator. Our approach contains two main techniques, an Enlarge-and-Repeat process and a Discrete Searching method, to craft mosaic-like adversarial vehicle textures without access to neither the model weight of the detector nor a differential rendering procedure. The experimental results demonstrate the effectiveness of our approach in the simulator.