 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-layer Attention Network for Fine-grained Visual Categorization
Paper and Code
Oct 17, 2022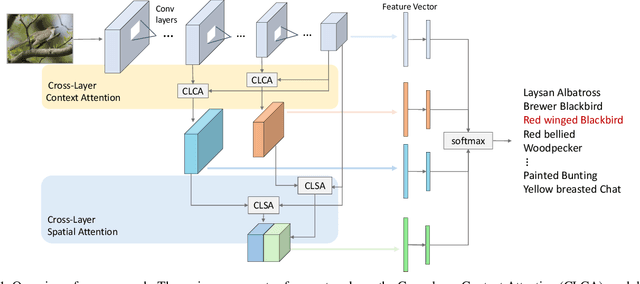
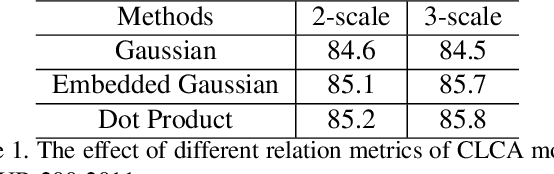
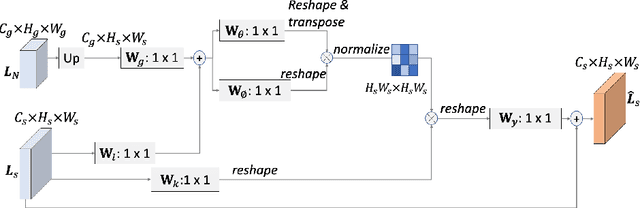
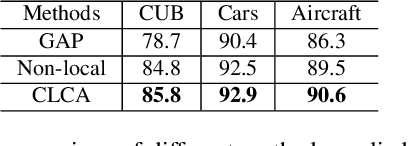
Learning discriminative representations for subtle localized details plays a significant role in Fine-grained Visual Categorization (FGVC). Compared to previous attention-based works, our work does not explicitly define or localize the part regions of interest; instead, we leverage the complementary properties of different stages of the network, and build a mutual refinement mechanism between the mid-level feature maps and the top-level feature map by our proposed Cross-layer Attention Network (CLAN). Specifically, CLAN is composed of 1) the Cross-layer Context Attention (CLCA) module, which enhances the global context information in the intermediate feature maps with the help of the top-level feature map, thereby improving the expressive power of the middle layers, and 2) the Cross-layer Spatial Attention (CLSA) module, which takes advantage of the local attention in the mid-level feature maps to boost the feature extraction of local regions at the top-level feature maps. Experimental results show our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft). Ablation studies and visualizations are provided to understand our approach. Experimental results show our approach achieves state-of-the-art on three publicly available fine-grained recognition datasets (CUB-200-2011, Stanford Cars and FGVC-Aircraft).