 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordSup: Exploiting Word Annotations for Character based Text Detection
Paper and Code
Aug 22, 2017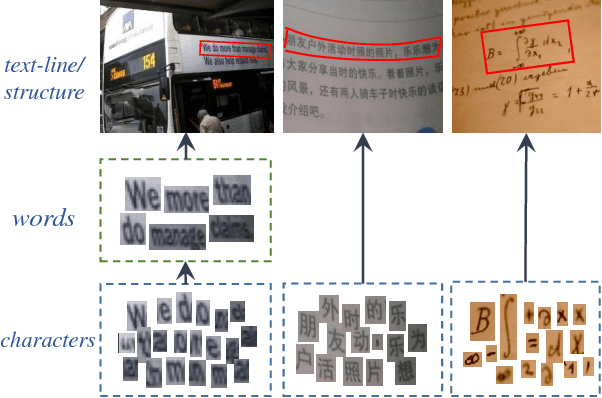
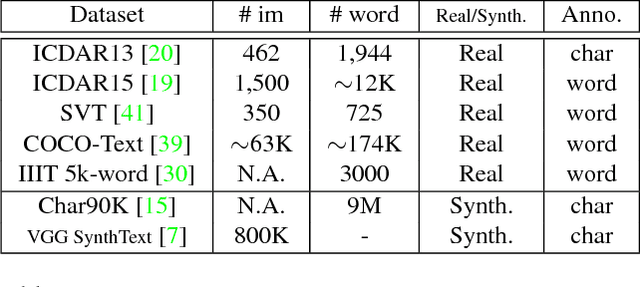
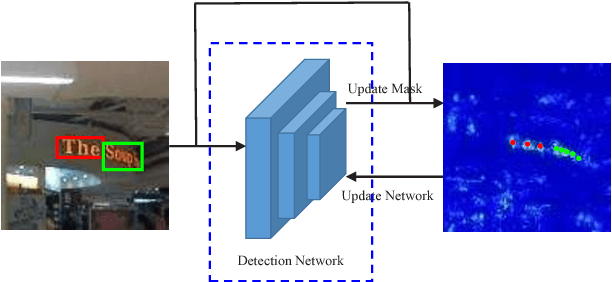
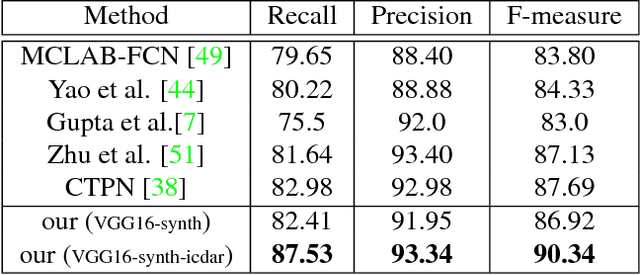
Imagery texts are usually organized as a hierarchy of several visual elements, i.e. characters, words, text lines and text blocks. Among these elements, character is the most basic one for various languages such as Western, Chinese, Japanese, mathematical expression and etc. It is natural and convenient to construct a common text detection engine based on character detectors. However, training character detectors requires a vast of location annotated characters, which are expensive to obtain. Actually, the existing real text datasets are mostly annotated in word or line level. To remedy this dilemma, we propose a weakly supervised framework that can utilize word annotations, either in tight quadrangles or the more loose bounding boxes, for character detector training. When applied in scene text detection, we are thus able to train a robust character detector by exploiting word annotations in the rich large-scale real scene text datasets, e.g. ICDAR15 and COCO-text. The character detector acts as a key role in the pipeline of our text detection engine. It achieves the state-of-the-art performance on several challenging scene text detection benchmarks. We also demonstrate the flexibility of our pipeline by various scenarios, including deformed text detection and math expression recognition.