 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Classifier-free Ensemble Selection Method based on Data Diversity in Random Subspaces
Paper and Code
Aug 13, 2014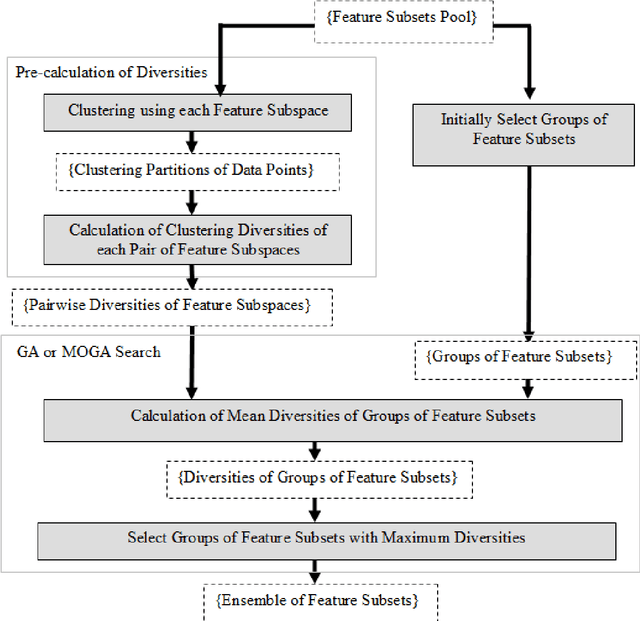

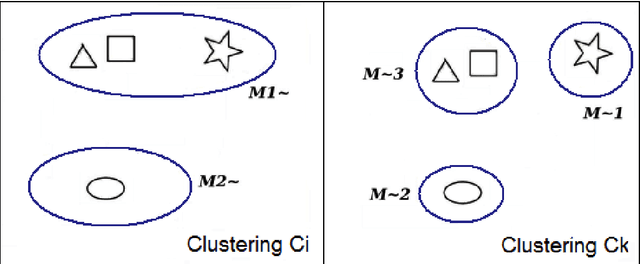

The Ensemble of Classifiers (EoC) has been shown to be effective in improving the performance of single classifiers by combining their outputs, and one of the most important properties involved in the selection of the best EoC from a pool of classifiers is considered to be classifier diversity. In general, classifier diversity does not occur randomly, but is generated systematically by various ensemble creation methods. By using diverse data subsets to train classifiers, these methods can create diverse classifiers for the EoC. In this work, we propose a scheme to measure data diversity directly from random subspaces, and explore the possibility of using it to select the best data subsets for the construction of the EoC. Our scheme is the first ensemble selection method to be presented in the literature based on the concept of data diversity. Its main advantage over the traditional framework (ensemble creation then selection) is that it obviates the need for classifier training prior to ensemble selection. A single Genetic Algorithm (GA) and a Multi-Objective Genetic Algorithm (MOGA) were evaluated to search for the best solutions for the classifier-free ensemble selection. In both cases, objective functions based on different clustering diversity measures were implemented and tested. All the results obtained with the proposed classifier-free ensemble selection method were compared with the traditional classifier-based ensemble selection using Mean Classifier Error (ME) and Majority Voting Error (MVE). The applicability of the method is tested on UCI machine learning problems and NIST SD19 handwritten numerals.