 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Different Annotation Strategies for Deployment of Parking Spaces Classification Systems
Jul 22, 2022

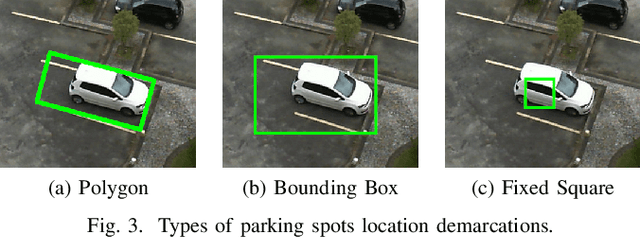
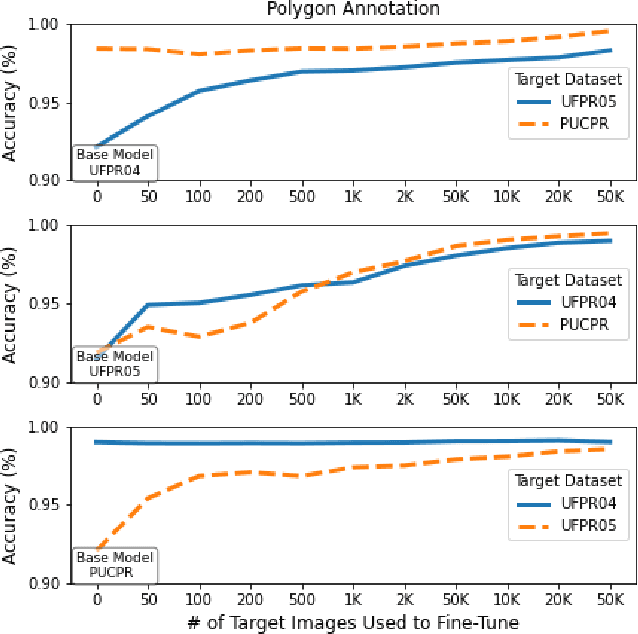
When using vision-based approaches to classify individual parking spaces between occupied and empty, human experts often need to annotate the locations and label a training set containing images collected in the target parking lot to fine-tune the system. We propose investigating three annotation types (polygons, bounding boxes, and fixed-size squares), providing different data representations of the parking spaces. The rationale is to elucidate the best trade-off between handcraft annotation precision and model performance. We also investigate the number of annotated parking spaces necessary to fine-tune a pre-trained model in the target parking lot. Experiments using the PKLot dataset show that it is possible to fine-tune a model to the target parking lot with less than 1,000 labeled samples, using low precision annotations such as fixed-size squares.