 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Feature Selection and Transfer Learning for Writer-Independent Offline Handwritten Signature Verification
Oct 19, 2020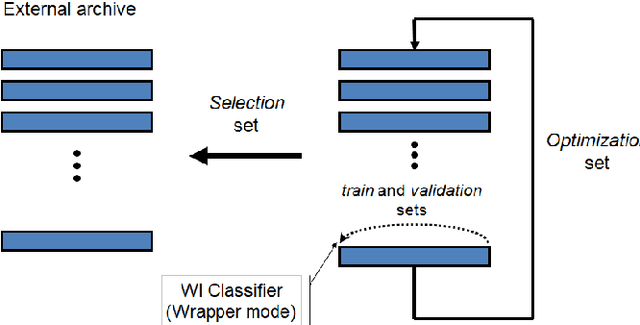
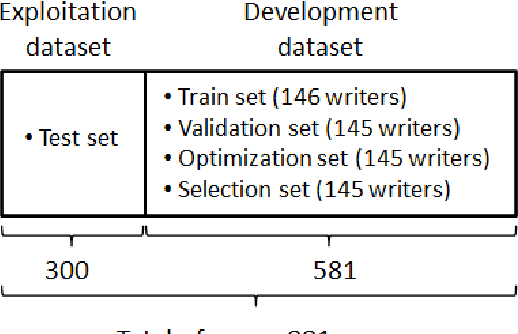
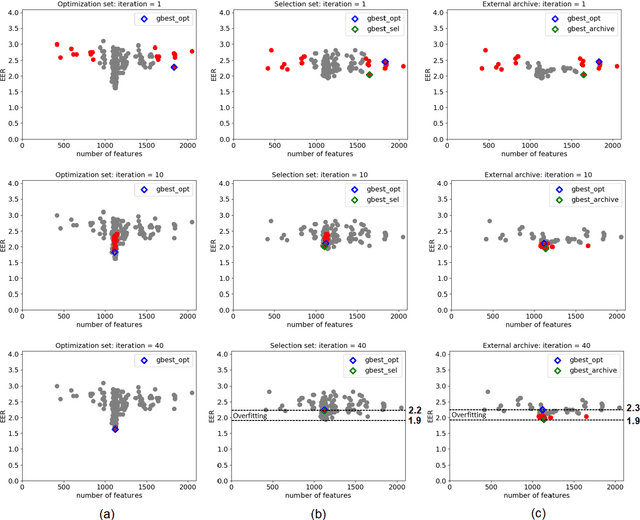

SigNet is a state of the art model for feature representation used for handwritten signature verification (HSV). This representation is based on a Deep Convolutional Neural Network (DCNN) and contains 2048 dimensions. When transposed to a dissimilarity space generated by the dichotomy transformation (DT), related to the writer-independent (WI) approach, these features may include redundant information. This paper investigates the presence of overfitting when using Binary Particle Swarm Optimization (BPSO) to perform the feature selection in a wrapper mode. We proposed a method based on a global validation strategy with an external archive to control overfitting during the search for the most discriminant representation. Moreover, an investigation is also carried out to evaluate the use of the selected features in a transfer learning context. The analysis is carried out on a writer-independent approach on the CEDAR, MCYT and GPDS datasets. The experimental results showed the presence of overfitting when no validation is used during the optimization process and the improvement when the global validation strategy with an external archive is used. Also, the space generated after feature selection can be used in a transfer learning context.
A white-box analysis on the writer-independent dichotomy transformation applied to offline handwritten signature verification
Apr 14, 2020

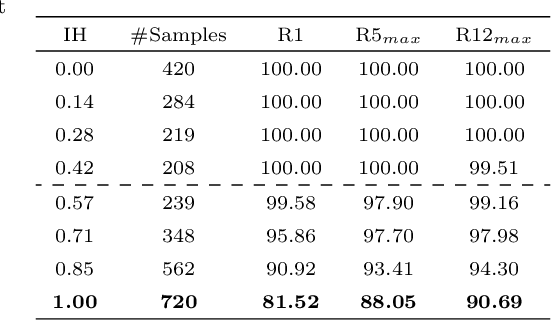
High number of writers, small number of training samples per writer with high intra-class variability and heavily imbalanced class distributions are among the challenges and difficulties of the offline Handwritten Signature Verification (HSV) problem. A good alternative to tackle these issues is to use a writer-independent (WI) framework. In WI systems, a single model is trained to perform signature verification for all writers from a dissimilarity space generated by the dichotomy transformation. Among the advantages of this framework is its scalability to deal with some of these challenges and its ease in managing new writers, and hence of being used in a transfer learning context. In this work, we present a white-box analysis of this approach highlighting how it handles the challenges, the dynamic selection of references through fusion function, and its application for transfer learning. All the analyses are carried out at the instance level using the instance hardness (IH) measure. The experimental results show that, using the IH analysis, we were able to characterize "good" and "bad" quality skilled forgeries as well as the frontier region between positive and negative samples. This enables futures investigations on methods for improving discrimination between genuine signatures and skilled forgeries by considering these characterizations.
Improving BPSO-based feature selection applied to offline WI handwritten signature verification through overfitting control
Apr 07, 2020
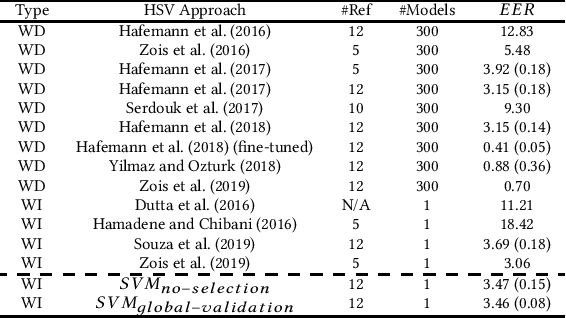
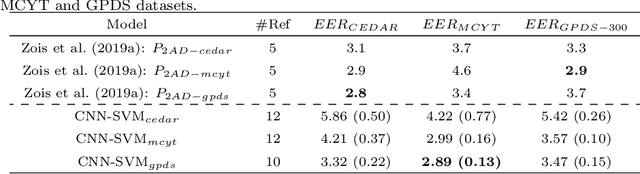
This paper investigates the presence of overfitting when using Binary Particle Swarm Optimization (BPSO) to perform the feature selection in a context of Handwritten Signature Verification (HSV). SigNet is a state of the art Deep CNN model for feature representation in the HSV context and contains 2048 dimensions. Some of these dimensions may include redundant information in the dissimilarity representation space generated by the dichotomy transformation (DT) used by the writer-independent (WI) approach. The analysis is carried out on the GPDS-960 dataset. Experiments demonstrate that the proposed method is able to control overfitting during the search for the most discriminant representation.
A writer-independent approach for offline signature verification using deep convolutional neural networks features
Jul 26, 2018



The use of features extracted using a deep convolutional neural network (CNN) combined with a writer-dependent (WD) SVM classifier resulted in significant improvement in performance of handwritten signature verification (HSV) when compared to the previous state-of-the-art methods. In this work it is investigated whether the use of these CNN features provide good results in a writer-independent (WI) HSV context, based on the dichotomy transformation combined with the use of an SVM writer-independent classifier. The experiments performed in the Brazilian and GPDS datasets show that (i) the proposed approach outperformed other WI-HSV methods from the literature, (ii) in the global threshold scenario, the proposed approach was able to outperform the writer-dependent method with CNN features in the Brazilian dataset, (iii) in an user threshold scenario, the results are similar to those obtained by the writer-dependent method with CNN features.