 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Acoustic Side-Channel Attacks on Noisy Keyboards Viable with LLM-Assisted Spectrograms' "Typo" Correction
Apr 15, 2025The large integration of microphones into devices increases the opportunities for Acoustic Side-Channel Attacks (ASCAs), as these can be used to capture keystrokes' audio signals that might reveal sensitive information. However, the current State-Of-The-Art (SOTA) models for ASCAs, including Convolutional Neural Networks (CNNs) and hybrid models, such as CoAtNet, still exhibit limited robustness under realistic noisy conditions. Solving this problem requires either: (i) an increased model's capacity to infer contextual information from longer sequences, allowing the model to learn that an initially noisily typed word is the same as a futurely collected non-noisy word, or (ii) an approach to fix misidentified information from the contexts, as one does not type random words, but the ones that best fit the conversation context. In this paper, we demonstrate that both strategies are viable and complementary solutions for making ASCAs practical. We observed that no existing solution leverages advanced transformer architectures' power for these tasks and propose that: (i) Visual Transformers (VTs) are the candidate solutions for capturing long-term contextual information and (ii) transformer-powered Large Language Models (LLMs) are the candidate solutions to fix the ``typos'' (mispredictions) the model might make. Thus, we here present the first-of-its-kind approach that integrates VTs and LLMs for ASCAs. We first show that VTs achieve SOTA performance in classifying keystrokes when compared to the previous CNN benchmark. Second, we demonstrate that LLMs can mitigate the impact of real-world noise. Evaluations on the natural sentences revealed that: (i) incorporating LLMs (e.g., GPT-4o) in our ASCA pipeline boosts the performance of error-correction tasks; and (ii) the comparable performance can be attained by a lightweight, fine-tuned smaller LLM (67 times smaller than GPT-4o), using...
Fast & Furious: Modelling Malware Detection as Evolving Data Streams
May 24, 2022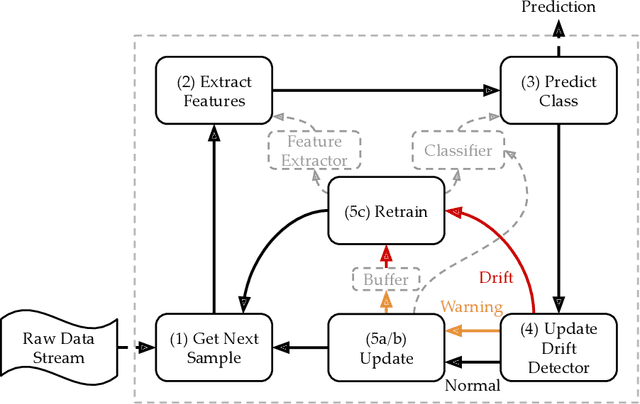
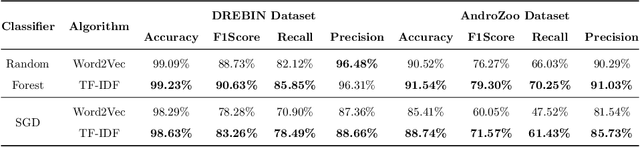
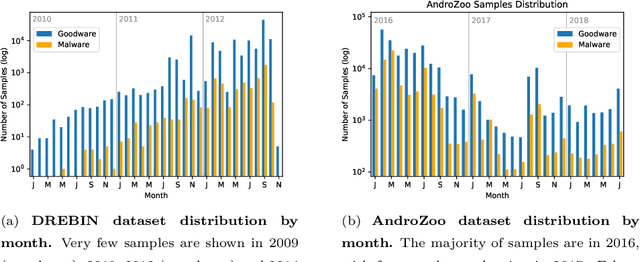
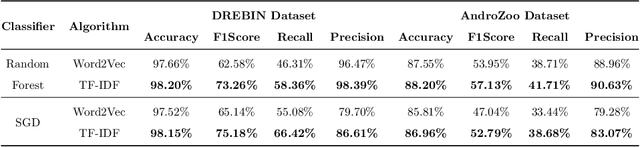
Malware is a major threat to computer systems and imposes many challenges to cyber security. Targeted threats, such as ransomware, cause millions of dollars in losses every year. The constant increase of malware infections has been motivating popular antiviruses (AVs) to develop dedicated detection strategies, which include meticulously crafted machine learning (ML) pipelines. However, malware developers unceasingly change their samples features to bypass detection. This constant evolution of malware samples causes changes to the data distribution (i.e., concept drifts) that directly affect ML model detection rates. In this work, we evaluate the impact of concept drift on malware classifiers for two Android datasets: DREBIN (~130K apps) and AndroZoo (~350K apps). Android is a ubiquitous operating system for smartphones, which stimulates attackers to regularly create and update malware to the platform. We conducted a longitudinal evaluation by (i) classifying malware samples collected over nine years (2009-2018), (ii) reviewing concept drift detection algorithms to attest its pervasiveness, (iii) comparing distinct ML approaches to mitigate the issue, and (iv) proposing an ML data stream pipeline that outperformed literature approaches. As a result, we observed that updating every component of the pipeline in response to concept drifts allows the classification model to achieve increasing detection rates as the data representation (extracted features) is updated. Furthermore, we discuss the impact of the changes on the classification models by comparing the variations in the extracted features.
Machine Learning (In) Security: A Stream of Problems
Oct 30, 2020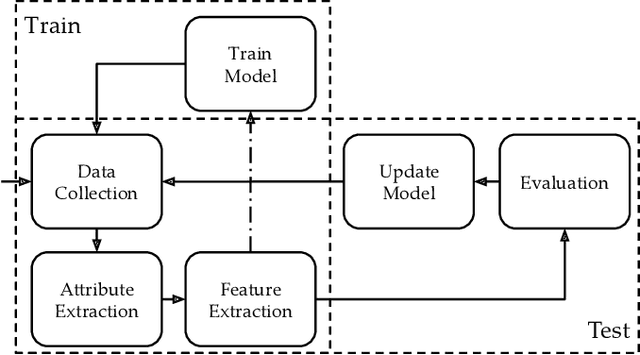
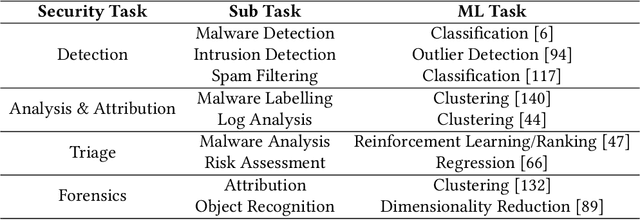

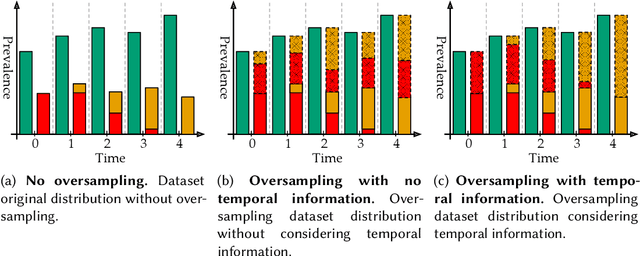
Machine Learning (ML) has been widely applied to cybersecurity, and is currently considered state-of-the-art for solving many of the field's open issues. However, it is very difficult to evaluate how good the produced solutions are, since the challenges faced in security may not appear in other areas (at least not in the same way). One of these challenges is the concept drift, that actually creates an arms race between attackers and defenders, given that any attacker may create novel, different threats as time goes by (to overcome defense solutions) and this "evolution" is not always considered in many works. Due to this type of issue, it is fundamental to know how to correctly build and evaluate a ML-based security solution. In this work, we list, detail, and discuss some of the challenges of applying ML to cybersecurity, including concept drift, concept evolution, delayed labels, and adversarial machine learning. We also show how existing solutions fail and, in some cases, we propose possible solutions to fix them.