 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast & Furious: Modelling Malware Detection as Evolving Data Streams
May 24, 2022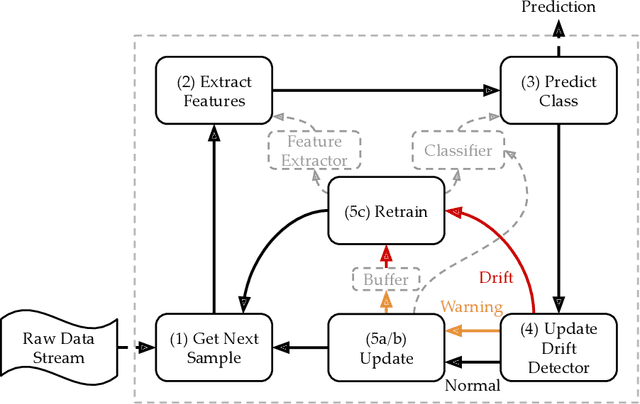
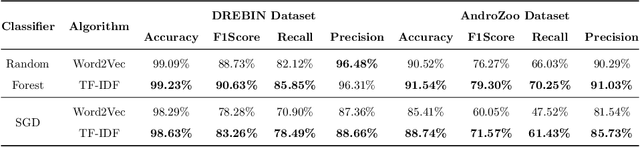
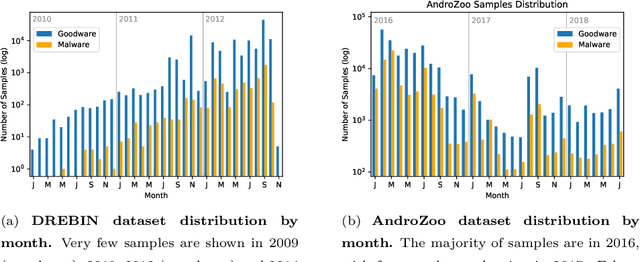
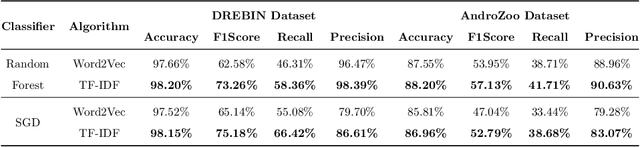
Malware is a major threat to computer systems and imposes many challenges to cyber security. Targeted threats, such as ransomware, cause millions of dollars in losses every year. The constant increase of malware infections has been motivating popular antiviruses (AVs) to develop dedicated detection strategies, which include meticulously crafted machine learning (ML) pipelines. However, malware developers unceasingly change their samples features to bypass detection. This constant evolution of malware samples causes changes to the data distribution (i.e., concept drifts) that directly affect ML model detection rates. In this work, we evaluate the impact of concept drift on malware classifiers for two Android datasets: DREBIN (~130K apps) and AndroZoo (~350K apps). Android is a ubiquitous operating system for smartphones, which stimulates attackers to regularly create and update malware to the platform. We conducted a longitudinal evaluation by (i) classifying malware samples collected over nine years (2009-2018), (ii) reviewing concept drift detection algorithms to attest its pervasiveness, (iii) comparing distinct ML approaches to mitigate the issue, and (iv) proposing an ML data stream pipeline that outperformed literature approaches. As a result, we observed that updating every component of the pipeline in response to concept drifts allows the classification model to achieve increasing detection rates as the data representation (extracted features) is updated. Furthermore, we discuss the impact of the changes on the classification models by comparing the variations in the extracted features.
Computer Users Have Unique Yet Temporally Inconsistent Computer Usage Profiles
May 20, 2021
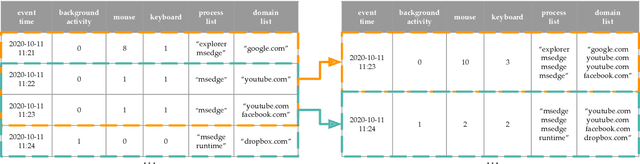
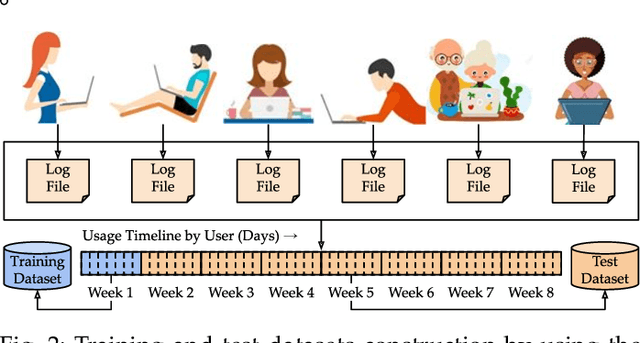
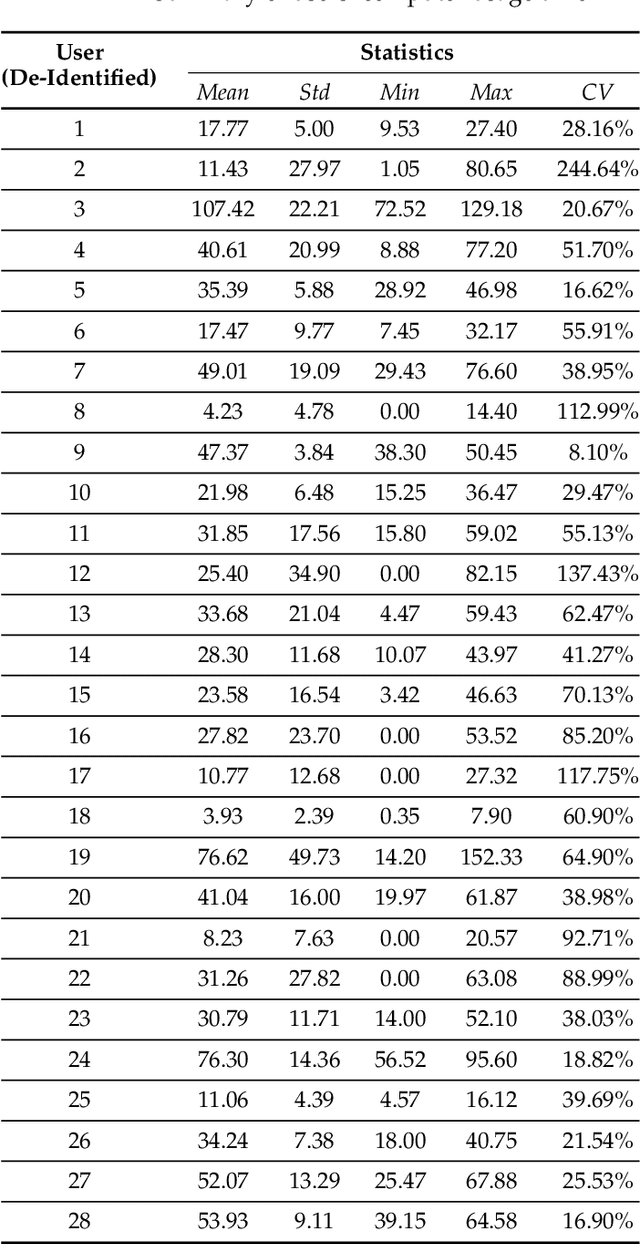
This paper investigates whether computer usage profiles comprised of process-, network-, mouse- and keystroke-related events are unique and temporally consistent in a naturalistic setting, discussing challenges and opportunities of using such profiles in applications of continuous authentication. We collected ecologically-valid computer usage profiles from 28 MS Windows 10 computer users over 8 weeks and submitted this data to comprehensive machine learning analysis involving a diverse set of online and offline classifiers. We found that (i) computer usage profiles have the potential to uniquely characterize computer users (with a maximum F-score of 99.94%); (ii) network-related events were the most useful features to properly recognize profiles (95.14% of the top features distinguishing users being network-related); (iii) user profiles were mostly inconsistent over the 8-week data collection period, with 92.86% of users exhibiting drifts in terms of time and usage habits; and (iv) online models are better suited to handle computer usage profiles compared to offline models (maximum F-score for each approach was 95.99% and 99.94%, respectively).
Predicting Misinformation and Engagement in COVID-19 Twitter Discourse in the First Months of the Outbreak
Dec 23, 2020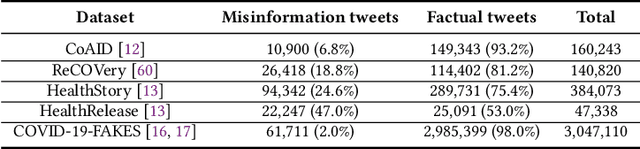
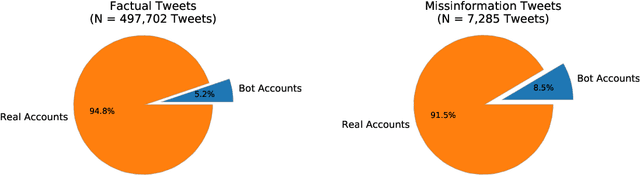
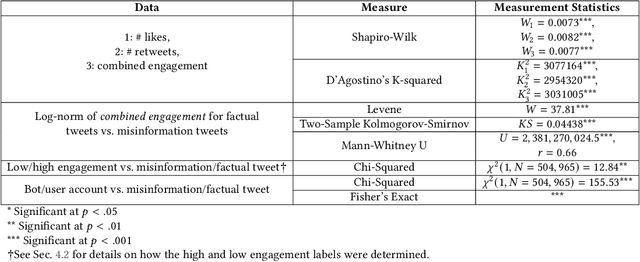
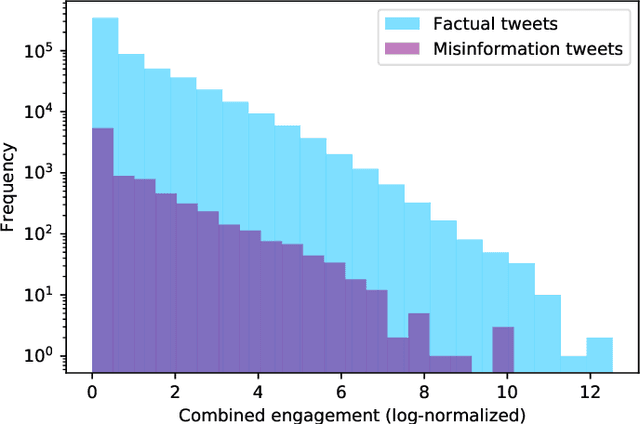
Disinformation entails the purposeful dissemination of falsehoods towards a greater dubious agenda and the chaotic fracturing of a society. The general public has grown aware of the misuse of social media towards these nefarious ends, where even global public health crises have not been immune to misinformation (deceptive content spread without intended malice). In this paper, we examine nearly 505K COVID-19-related tweets from the initial months of the pandemic to understand misinformation as a function of bot-behavior and engagement. Using a correlation-based feature selection method, we selected the 11 most relevant feature subsets among over 170 features to distinguish misinformation from facts, and to predict highly engaging misinformation tweets about COVID-19. We achieved an average F-score of at least 72\% with ten popular multi-class classifiers, reinforcing the relevance of the selected features. We found that (i) real users tweet both facts and misinformation, while bots tweet proportionally more misinformation; (ii) misinformation tweets were less engaging than facts; (iii) the textual content of a tweet was the most important to distinguish fact from misinformation while (iv) user account metadata and human-like activity were most important to predict high engagement in factual and misinformation tweets; and (v) sentiment features were not relevant.
Machine Learning (In) Security: A Stream of Problems
Oct 30, 2020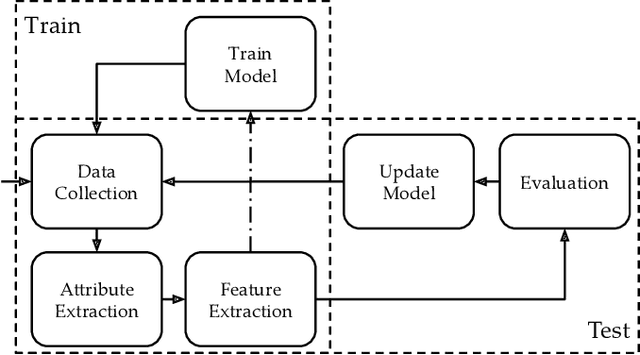
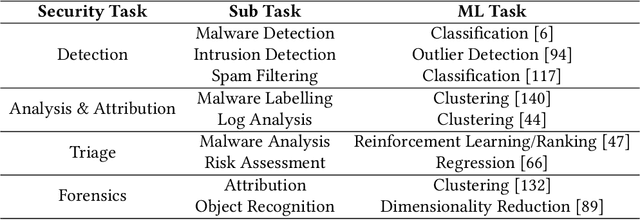

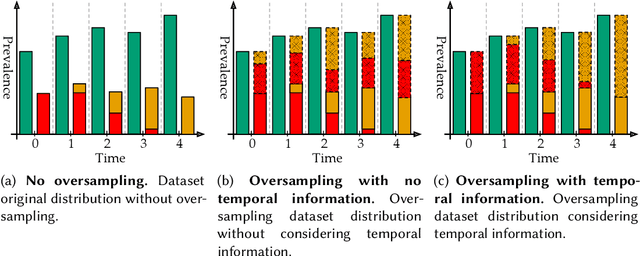
Machine Learning (ML) has been widely applied to cybersecurity, and is currently considered state-of-the-art for solving many of the field's open issues. However, it is very difficult to evaluate how good the produced solutions are, since the challenges faced in security may not appear in other areas (at least not in the same way). One of these challenges is the concept drift, that actually creates an arms race between attackers and defenders, given that any attacker may create novel, different threats as time goes by (to overcome defense solutions) and this "evolution" is not always considered in many works. Due to this type of issue, it is fundamental to know how to correctly build and evaluate a ML-based security solution. In this work, we list, detail, and discuss some of the challenges of applying ML to cybersecurity, including concept drift, concept evolution, delayed labels, and adversarial machine learning. We also show how existing solutions fail and, in some cases, we propose possible solutions to fix them.