 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Semi-Supervised Learning for Delayed Partially Labelled Data Streams
Paper and Code
Jun 16, 2021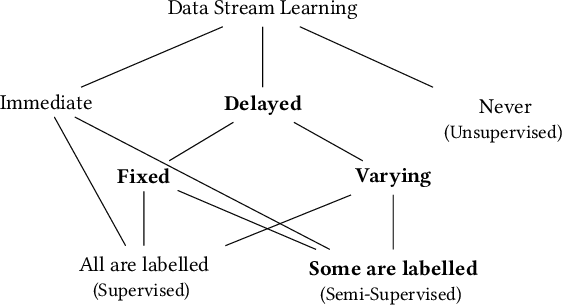
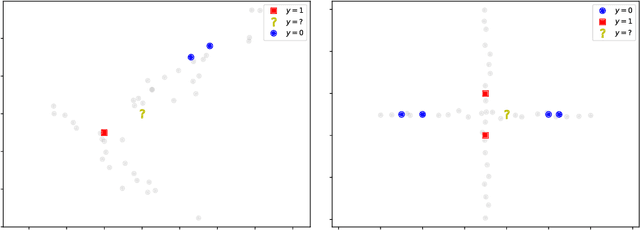
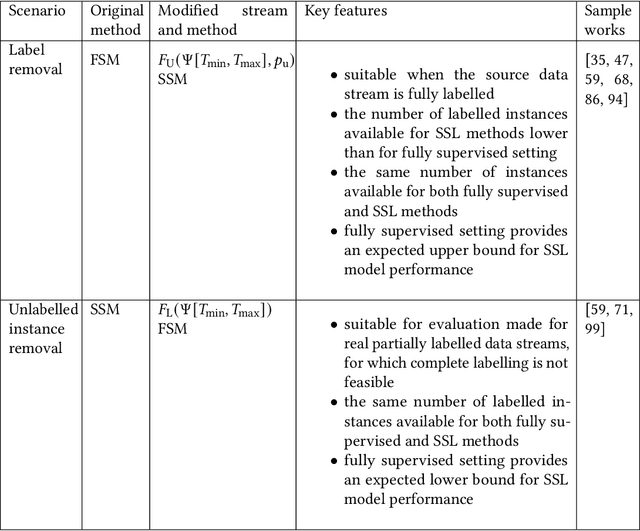
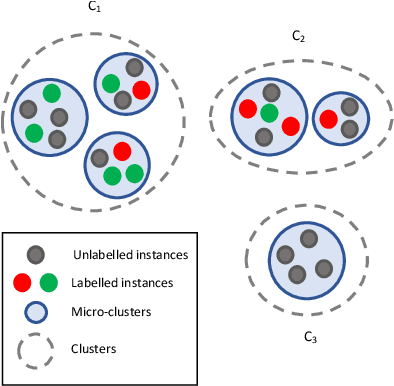
Unlabelled data appear in many domains and are particularly relevant to streaming applications, where even though data is abundant, labelled data is rare. To address the learning problems associated with such data, one can ignore the unlabelled data and focus only on the labelled data (supervised learning); use the labelled data and attempt to leverage the unlabelled data (semi-supervised learning); or assume some labels will be available on request (active learning). The first approach is the simplest, yet the amount of labelled data available will limit the predictive performance. The second relies on finding and exploiting the underlying characteristics of the data distribution. The third depends on an external agent to provide the required labels in a timely fashion. This survey pays special attention to methods that leverage unlabelled data in a semi-supervised setting. We also discuss the delayed labelling issue, which impacts both fully supervised and semi-supervised methods. We propose a unified problem setting, discuss the learning guarantees and existing methods, explain the differences between related problem settings. Finally, we review the current benchmarking practices and propose adaptations to enhance them.