 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELODIN: Naming Concepts in Embedding Spaces
Mar 09, 2023



Despite recent advancements, the field of text-to-image synthesis still suffers from lack of fine-grained control. Using only text, it remains challenging to deal with issues such as concept coherence and concept contamination. We propose a method to enhance control by generating specific concepts that can be reused throughout multiple images, effectively expanding natural language with new words that can be combined much like a painter's palette. Unlike previous contributions, our method does not copy visuals from input data and can generate concepts through text alone. We perform a set of comparisons that finds our method to be a significant improvement over text-only prompts.
A Survey on Semi-Supervised Learning for Delayed Partially Labelled Data Streams
Jun 16, 2021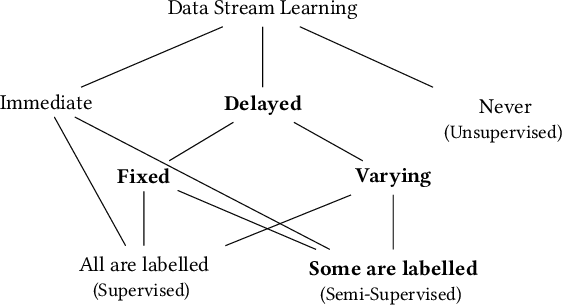
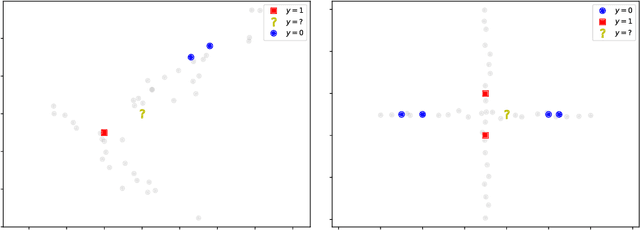
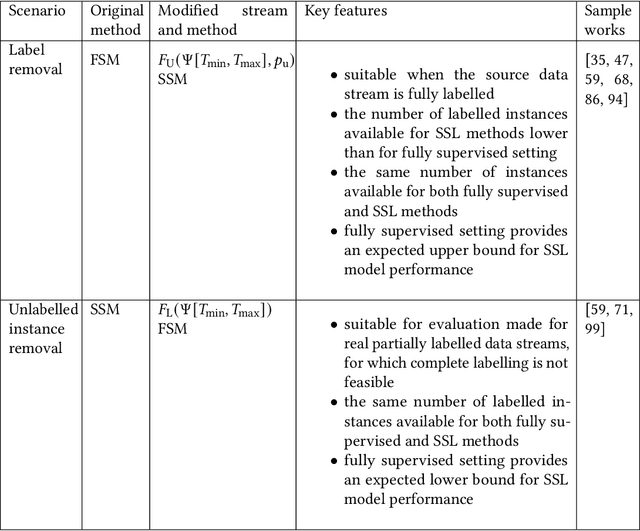
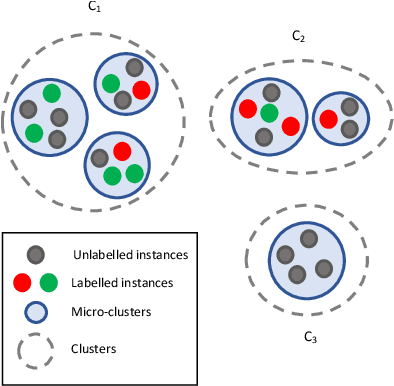
Unlabelled data appear in many domains and are particularly relevant to streaming applications, where even though data is abundant, labelled data is rare. To address the learning problems associated with such data, one can ignore the unlabelled data and focus only on the labelled data (supervised learning); use the labelled data and attempt to leverage the unlabelled data (semi-supervised learning); or assume some labels will be available on request (active learning). The first approach is the simplest, yet the amount of labelled data available will limit the predictive performance. The second relies on finding and exploiting the underlying characteristics of the data distribution. The third depends on an external agent to provide the required labels in a timely fashion. This survey pays special attention to methods that leverage unlabelled data in a semi-supervised setting. We also discuss the delayed labelling issue, which impacts both fully supervised and semi-supervised methods. We propose a unified problem setting, discuss the learning guarantees and existing methods, explain the differences between related problem settings. Finally, we review the current benchmarking practices and propose adaptations to enhance them.
Ensuring Learning Guarantees on Concept Drift Detection with Statistical Learning Theory
Jun 24, 2020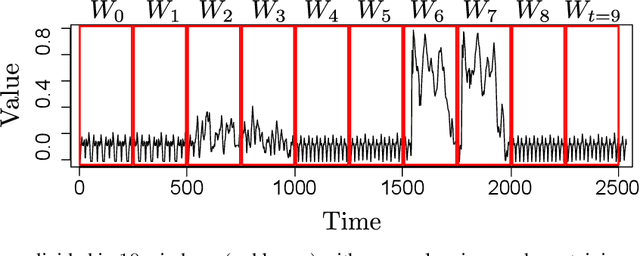


Concept Drift (CD) detection intends to continuously identify changes in data stream behaviors, supporting researchers in the study and modeling of real-world phenomena. Motivated by the lack of learning guarantees in current CD algorithms, we decided to take advantage of the Statistical Learning Theory (SLT) to formalize the necessary requirements to ensure probabilistic learning bounds, so drifts would refer to actual changes in data rather than by chance. As discussed along this paper, a set of mathematical assumptions must be held in order to rely on SLT bounds, which are especially controversial in CD scenarios. Based on this issue, we propose a methodology to address those assumptions in CD scenarios and therefore ensure learning guarantees. Complementary, we assessed a set of relevant and known CD algorithms from the literature in light of our methodology. As main contribution, we expect this work to support researchers while designing and evaluating CD algorithms on different domains.
Supporting Optimal Phase Space Reconstructions Using Neural Network Architecture for Time Series Modeling
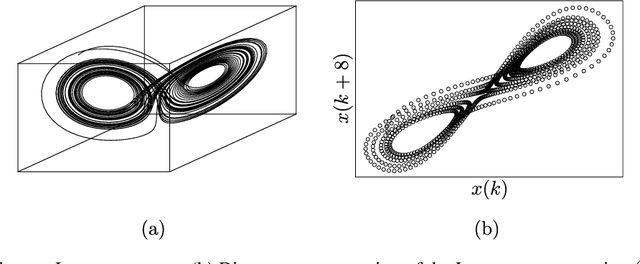
Jun 19, 2020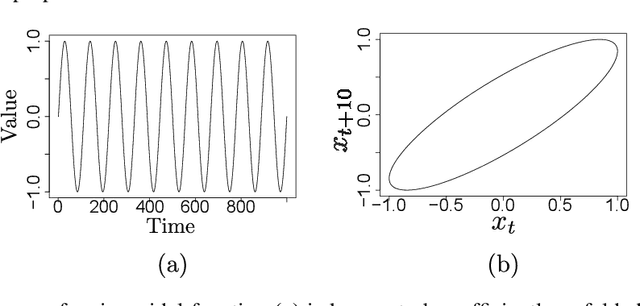
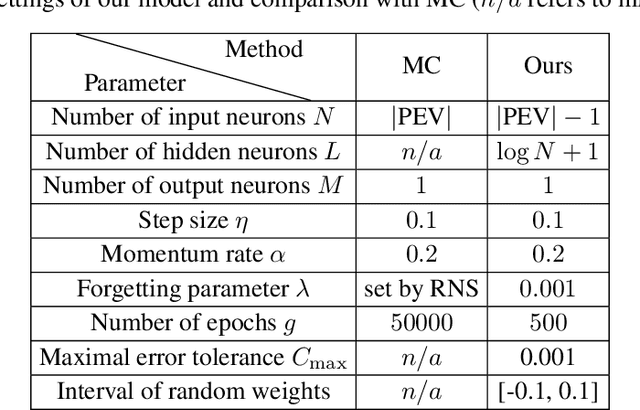
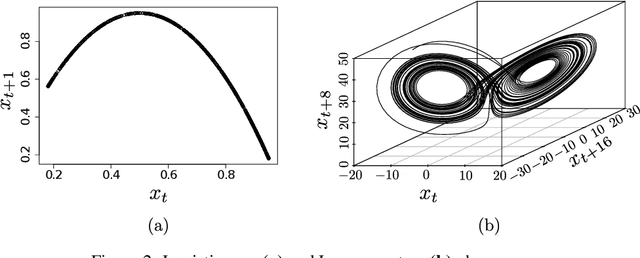
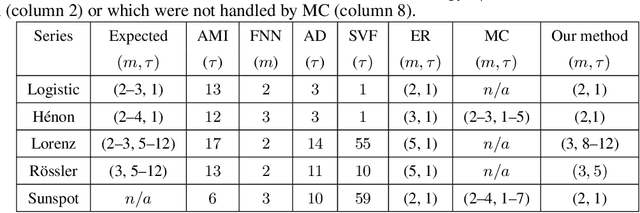
The reconstruction of phase spaces is an essential step to analyze time series according to Dynamical System concepts. A regression performed on such spaces unveils the relationships among system states from which we can derive their generating rules, that is, the most probable set of functions responsible for generating observations along time. In this sense, most approaches rely on Takens' embedding theorem to unfold the phase space, which requires the embedding dimension and the time delay. Moreover, although several methods have been proposed to empirically estimate those parameters, they still face limitations due to their lack of consistency and robustness, which has motivated this paper. As an alternative, we here propose an artificial neural network with a forgetting mechanism to implicitly learn the phase spaces properties, whatever they are. Such network trains on forecasting errors and, after converging, its architecture is used to estimate the embedding parameters. Experimental results confirm that our approach is either as competitive as or better than most state-of-the-art strategies while revealing the temporal relationship among time-series observations.