 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances on Concept Drift Detection in Regression Tasks using Social Networks Theory
Apr 19, 2023Mining data streams is one of the main studies in machine learning area due to its application in many knowledge areas. One of the major challenges on mining data streams is concept drift, which requires the learner to discard the current concept and adapt to a new one. Ensemble-based drift detection algorithms have been used successfully to the classification task but usually maintain a fixed size ensemble of learners running the risk of needlessly spending processing time and memory. In this paper we present improvements to the Scale-free Network Regressor (SFNR), a dynamic ensemble-based method for regression that employs social networks theory. In order to detect concept drifts SFNR uses the Adaptive Window (ADWIN) algorithm. Results show improvements in accuracy, especially in concept drift situations and better performance compared to other state-of-the-art algorithms in both real and synthetic data.
Estimating action plans for smart poultry houses
Aug 17, 2020
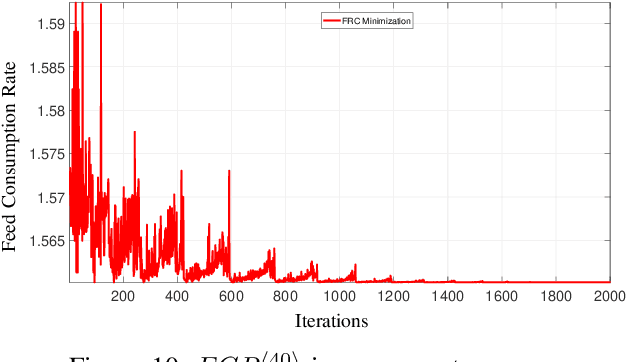
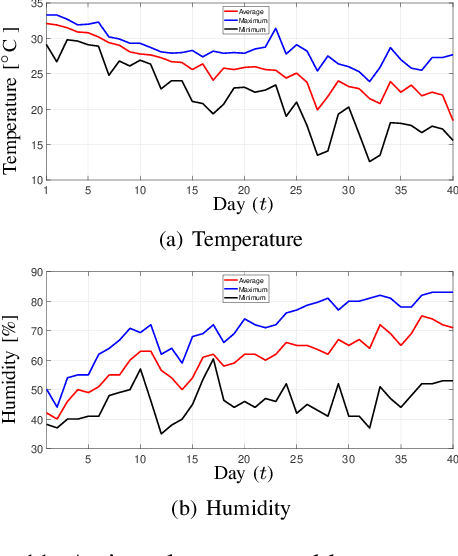

In poultry farming, the systematic choice, update, and implementation of periodic (t) action plans define the feed conversion rate (FCR[t]), which is an acceptable measure for successful production. Appropriate action plans provide tailored resources for broilers, allowing them to grow within the so-called thermal comfort zone, without wast or lack of resources. Although the implementation of an action plan is automatic, its configuration depends on the knowledge of the specialist, tending to be inefficient and error-prone, besides to result in different FCR[t] for each poultry house. In this article, we claim that the specialist's perception can be reproduced, to some extent, by computational intelligence. By combining deep learning and genetic algorithm techniques, we show how action plans can adapt their performance over the time, based on previous well succeeded plans. We also implement a distributed network infrastructure that allows to replicate our method over distributed poultry houses, for their smart, interconnected, and adaptive control. A supervision system is provided as interface to users. Experiments conducted over real data show that our method improves 5% on the performance of the most productive specialist, staying very close to the optimal FCR[t].