 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Classification of Time Series in Non-Stationary Cost Regimes
Jan 31, 2026Early Classification of Time Series (ECTS) addresses decision-making problems in which predictions must be made as early as possible while maintaining high accuracy. Most existing ECTS methods assume that the time-dependent decision costs governing the learning objective are known, fixed, and correctly specified. In practice, however, these costs are often uncertain and may change over time, leading to mismatches between training-time and deployment-time objectives. In this paper, we study ECTS under two practically relevant forms of cost non-stationarity: drift in the balance between misclassification and decision delay costs, and stochastic realizations of decision costs that deviate from the nominal training-time model. To address these challenges, we revisit representative ECTS approaches and adapt them to an online learning setting. Focusing on separable methods, we update only the triggering model during deployment, while keeping the classifier fixed. We propose several online adaptations and baselines, including bandit-based and RL-based approaches, and conduct controlled experiments on synthetic data to systematically evaluate robustness under cost non-stationarity. Our results demonstrate that online learning can effectively improve the robustness of ECTS methods to cost drift, with RL-based strategies exhibiting strong and stable performance across varying cost regimes.
Deep Reinforcement Learning based Triggering Function for Early Classifiers of Time Series
Feb 10, 2025



Early Classification of Time Series (ECTS) has been recognized as an important problem in many areas where decisions have to be taken as soon as possible, before the full data availability, while time pressure increases. Numerous ECTS approaches have been proposed, based on different triggering functions, each taking into account various pieces of information related to the incoming time series and/or the output of a classifier. Although their performances have been empirically compared in the literature, no studies have been carried out on the optimality of these triggering functions that involve ``man-tailored'' decision rules. Based on the same information, could there be better triggering functions? This paper presents one way to investigate this question by showing first how to translate ECTS problems into Reinforcement Learning (RL) ones, where the very same information is used in the state space. A thorough comparison of the performance obtained by ``handmade'' approaches and their ``RL-based'' counterparts has been carried out. A second question investigated in this paper is whether a different combination of information, defining the state space in RL systems, can achieve even better performance. Experiments show that the system we describe, called \textsc{Alert}, significantly outperforms its state-of-the-art competitors on a large number of datasets.
Mislabeled examples detection viewed as probing machine learning models: concepts, survey and extensive benchmark
Oct 21, 2024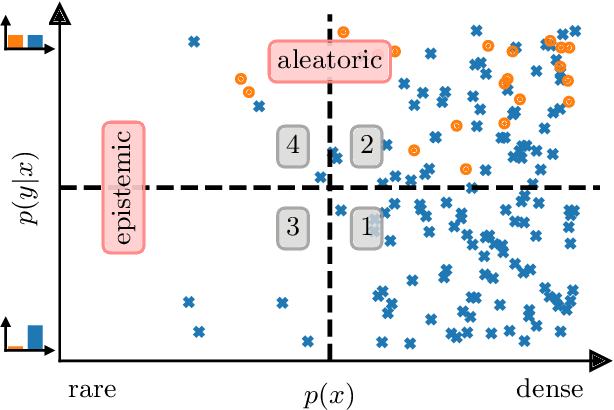
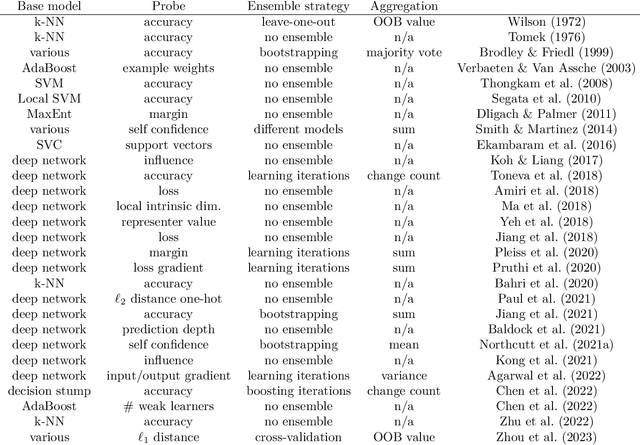
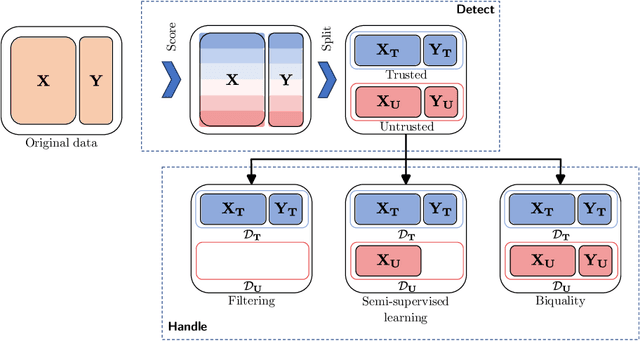
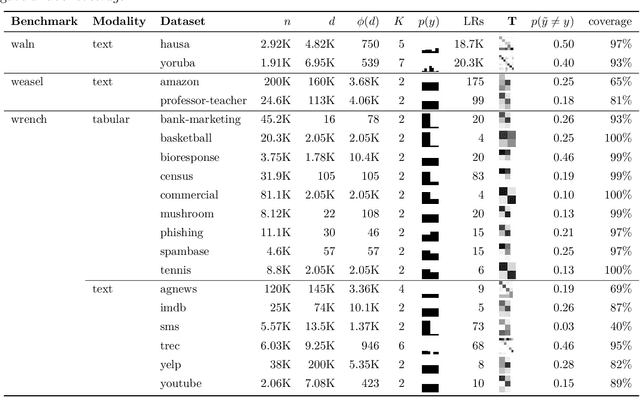
Mislabeled examples are ubiquitous in real-world machine learning datasets, advocating the development of techniques for automatic detection. We show that most mislabeled detection methods can be viewed as probing trained machine learning models using a few core principles. We formalize a modular framework that encompasses these methods, parameterized by only 4 building blocks, as well as a Python library that demonstrates that these principles can actually be implemented. The focus is on classifier-agnostic concepts, with an emphasis on adapting methods developed for deep learning models to non-deep classifiers for tabular data. We benchmark existing methods on (artificial) Completely At Random (NCAR) as well as (realistic) Not At Random (NNAR) labeling noise from a variety of tasks with imperfect labeling rules. This benchmark provides new insights as well as limitations of existing methods in this setup.
ml_edm package: a Python toolkit for Machine Learning based Early Decision Making
Aug 23, 2024
\texttt{ml\_edm} is a Python 3 library, designed for early decision making of any learning tasks involving temporal/sequential data. The package is also modular, providing researchers an easy way to implement their own triggering strategy for classification, regression or any machine learning task. As of now, many Early Classification of Time Series (ECTS) state-of-the-art algorithms, are efficiently implemented in the library leveraging parallel computation. The syntax follows the one introduce in \texttt{scikit-learn}, making estimators and pipelines compatible with \texttt{ml\_edm}. This software is distributed over the BSD-3-Clause license, source code can be found at \url{https://github.com/ML-EDM/ml_edm}.
Early Classification of Time Series: Taxonomy and Benchmark
Jun 26, 2024



In many situations, the measurements of a studied phenomenon are provided sequentially, and the prediction of its class needs to be made as early as possible so as not to incur too high a time penalty, but not too early and risk paying the cost of misclassification. This problem has been particularly studied in the case of time series, and is known as Early Classification of Time Series (ECTS). Although it has been the subject of a growing body of literature, there is still a lack of a systematic, shared evaluation protocol to compare the relative merits of the various existing methods. This document begins by situating these methods within a principle-based taxonomy. It defines dimensions for organizing their evaluation, and then reports the results of a very extensive set of experiments along these dimensions involving nine state-of-the art ECTS algorithms. In addition, these and other experiments can be carried out using an open-source library in which most of the existing ECTS algorithms have been implemented (see \url{https://github.com/ML-EDM/ml_edm}).
Biquality Learning: a Framework to Design Algorithms Dealing with Closed-Set Distribution Shifts
Aug 29, 2023Training machine learning models from data with weak supervision and dataset shifts is still challenging. Designing algorithms when these two situations arise has not been explored much, and existing algorithms cannot always handle the most complex distributional shifts. We think the biquality data setup is a suitable framework for designing such algorithms. Biquality Learning assumes that two datasets are available at training time: a trusted dataset sampled from the distribution of interest and the untrusted dataset with dataset shifts and weaknesses of supervision (aka distribution shifts). The trusted and untrusted datasets available at training time make designing algorithms dealing with any distribution shifts possible. We propose two methods, one inspired by the label noise literature and another by the covariate shift literature for biquality learning. We experiment with two novel methods to synthetically introduce concept drift and class-conditional shifts in real-world datasets across many of them. We opened some discussions and assessed that developing biquality learning algorithms robust to distributional changes remains an interesting problem for future research.
biquality-learn: a Python library for Biquality Learning
Aug 18, 2023
The democratization of Data Mining has been widely successful thanks in part to powerful and easy-to-use Machine Learning libraries. These libraries have been particularly tailored to tackle Supervised Learning. However, strong supervision signals are scarce in practice, and practitioners must resort to weak supervision. In addition to weaknesses of supervision, dataset shifts are another kind of phenomenon that occurs when deploying machine learning models in the real world. That is why Biquality Learning has been proposed as a machine learning framework to design algorithms capable of handling multiple weaknesses of supervision and dataset shifts without assumptions on their nature and level by relying on the availability of a small trusted dataset composed of cleanly labeled and representative samples. Thus we propose biquality-learn: a Python library for Biquality Learning with an intuitive and consistent API to learn machine learning models from biquality data, with well-proven algorithms, accessible and easy to use for everyone, and enabling researchers to experiment in a reproducible way on biquality data.
Automatic Feature Engineering for Time Series Classification: Evaluation and Discussion
Aug 02, 2023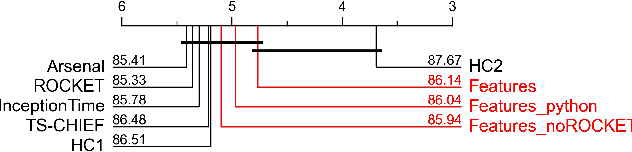



Time Series Classification (TSC) has received much attention in the past two decades and is still a crucial and challenging problem in data science and knowledge engineering. Indeed, along with the increasing availability of time series data, many TSC algorithms have been suggested by the research community in the literature. Besides state-of-the-art methods based on similarity measures, intervals, shapelets, dictionaries, deep learning methods or hybrid ensemble methods, several tools for extracting unsupervised informative summary statistics, aka features, from time series have been designed in the recent years. Originally designed for descriptive analysis and visualization of time series with informative and interpretable features, very few of these feature engineering tools have been benchmarked for TSC problems and compared with state-of-the-art TSC algorithms in terms of predictive performance. In this article, we aim at filling this gap and propose a simple TSC process to evaluate the potential predictive performance of the feature sets obtained with existing feature engineering tools. Thus, we present an empirical study of 11 feature engineering tools branched with 9 supervised classifiers over 112 time series data sets. The analysis of the results of more than 10000 learning experiments indicate that feature-based methods perform as accurately as current state-of-the-art TSC algorithms, and thus should rightfully be considered further in the TSC literature.
Open challenges for Machine Learning based Early Decision-Making research
Apr 27, 2022
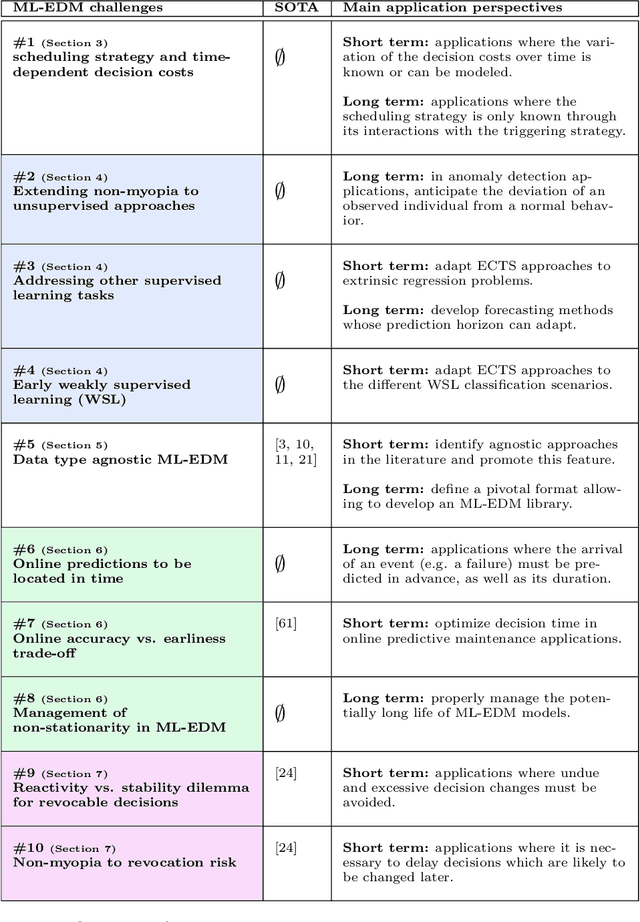
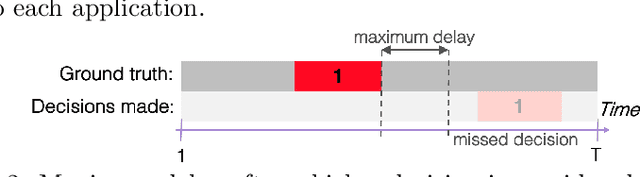
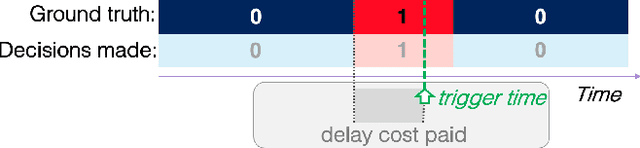
More and more applications require early decisions, i.e. taken as soon as possible from partially observed data. However, the later a decision is made, the more its accuracy tends to improve, since the description of the problem to hand is enriched over time. Such a compromise between the earliness and the accuracy of decisions has been particularly studied in the field of Early Time Series Classification. This paper introduces a more general problem, called Machine Learning based Early Decision Making (ML-EDM), which consists in optimizing the decision times of models in a wide range of settings where data is collected over time. After defining the ML-EDM problem, ten challenges are identified and proposed to the scientific community to further research in this area. These challenges open important application perspectives, discussed in this paper.
ECOTS: Early Classification in Open Time Series
Apr 01, 2022


Learning to predict ahead of time events in open time series is challenging. While Early Classification of Time Series (ECTS) tackles the problem of balancing online the accuracy of the prediction with the cost of delaying the decision when the individuals are time series of finite length with a unique label for the whole time series. Surprisingly, this trade-off has never been investigated for open time series with undetermined length and with different classes for each subsequence of the same time series. In this paper, we propose a principled method to adapt any technique for ECTS to the Early Classification in Open Time Series (ECOTS). We show how the classifiers must be constructed and what the decision triggering system becomes in this new scenario. We address the challenge of decision making in the predictive maintenance field. We illustrate our methodology by transforming two state-of-the-art ECTS algorithms for the ECOTS scenario and report numerical experiments on a real dataset for predictive maintenance that demonstrate the practicality of the novel approach.