 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMislabeled examples detection viewed as probing machine learning models: concepts, survey and extensive benchmark
Oct 21, 2024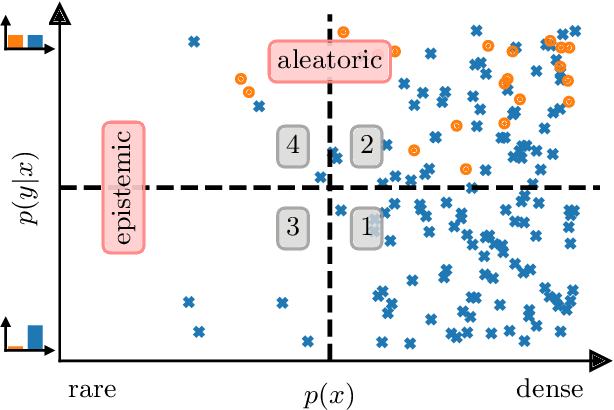
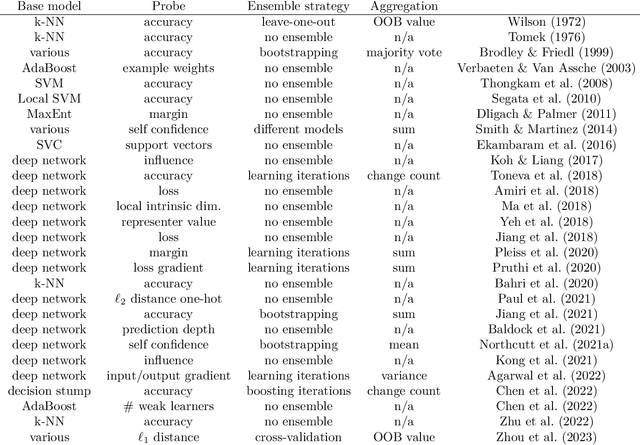
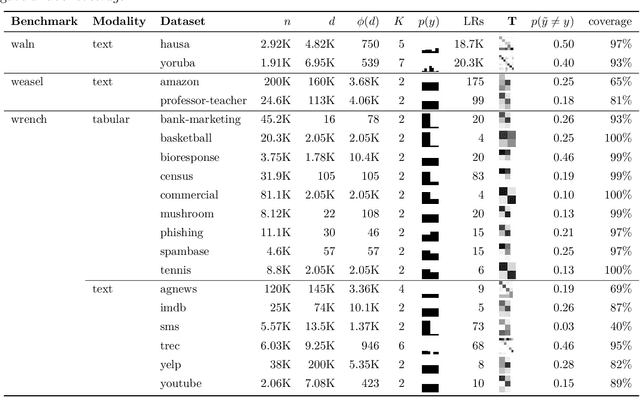
Mislabeled examples are ubiquitous in real-world machine learning datasets, advocating the development of techniques for automatic detection. We show that most mislabeled detection methods can be viewed as probing trained machine learning models using a few core principles. We formalize a modular framework that encompasses these methods, parameterized by only 4 building blocks, as well as a Python library that demonstrates that these principles can actually be implemented. The focus is on classifier-agnostic concepts, with an emphasis on adapting methods developed for deep learning models to non-deep classifiers for tabular data. We benchmark existing methods on (artificial) Completely At Random (NCAR) as well as (realistic) Not At Random (NNAR) labeling noise from a variety of tasks with imperfect labeling rules. This benchmark provides new insights as well as limitations of existing methods in this setup.
Biquality Learning: a Framework to Design Algorithms Dealing with Closed-Set Distribution Shifts
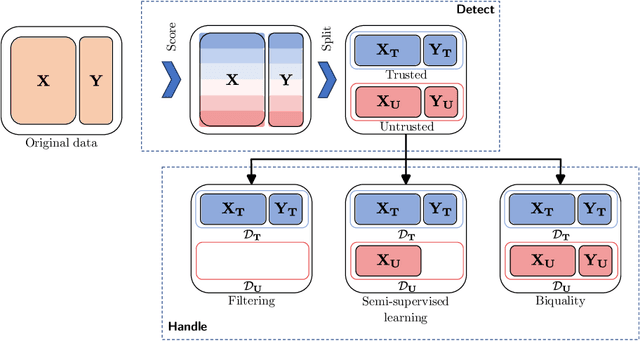
Aug 29, 2023Training machine learning models from data with weak supervision and dataset shifts is still challenging. Designing algorithms when these two situations arise has not been explored much, and existing algorithms cannot always handle the most complex distributional shifts. We think the biquality data setup is a suitable framework for designing such algorithms. Biquality Learning assumes that two datasets are available at training time: a trusted dataset sampled from the distribution of interest and the untrusted dataset with dataset shifts and weaknesses of supervision (aka distribution shifts). The trusted and untrusted datasets available at training time make designing algorithms dealing with any distribution shifts possible. We propose two methods, one inspired by the label noise literature and another by the covariate shift literature for biquality learning. We experiment with two novel methods to synthetically introduce concept drift and class-conditional shifts in real-world datasets across many of them. We opened some discussions and assessed that developing biquality learning algorithms robust to distributional changes remains an interesting problem for future research.
biquality-learn: a Python library for Biquality Learning
Aug 18, 2023
The democratization of Data Mining has been widely successful thanks in part to powerful and easy-to-use Machine Learning libraries. These libraries have been particularly tailored to tackle Supervised Learning. However, strong supervision signals are scarce in practice, and practitioners must resort to weak supervision. In addition to weaknesses of supervision, dataset shifts are another kind of phenomenon that occurs when deploying machine learning models in the real world. That is why Biquality Learning has been proposed as a machine learning framework to design algorithms capable of handling multiple weaknesses of supervision and dataset shifts without assumptions on their nature and level by relying on the availability of a small trusted dataset composed of cleanly labeled and representative samples. Thus we propose biquality-learn: a Python library for Biquality Learning with an intuitive and consistent API to learn machine learning models from biquality data, with well-proven algorithms, accessible and easy to use for everyone, and enabling researchers to experiment in a reproducible way on biquality data.
Contrastive Representations for Label Noise Require Fine-Tuning
Aug 20, 2021

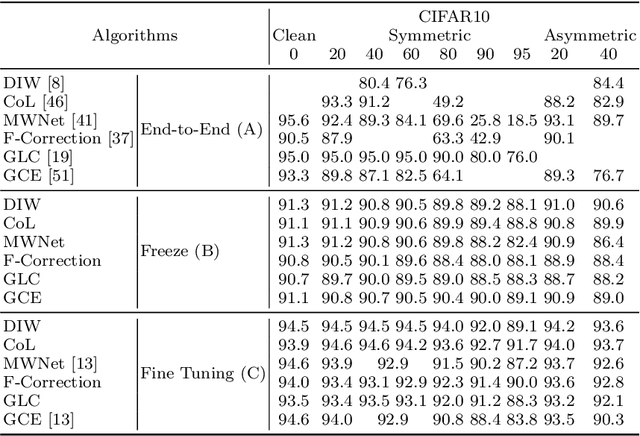
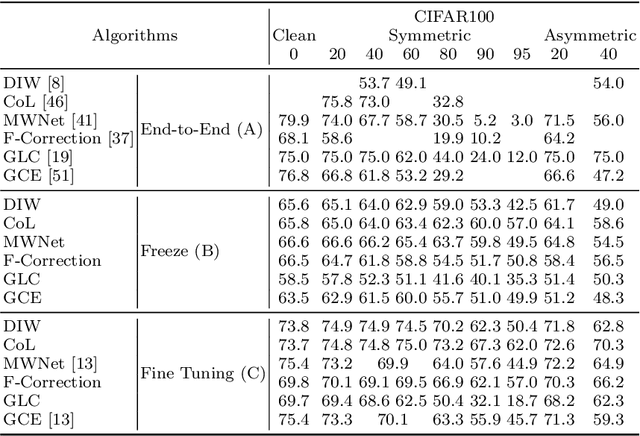
In this paper we show that the combination of a Contrastive representation with a label noise-robust classification head requires fine-tuning the representation in order to achieve state-of-the-art performances. Since fine-tuned representations are shown to outperform frozen ones, one can conclude that noise-robust classification heads are indeed able to promote meaningful representations if provided with a suitable starting point. Experiments are conducted to draw a comprehensive picture of performances by featuring six methods and nine noise instances of three different kinds (none, symmetric, and asymmetric). In presence of noise the experiments show that fine tuning of Contrastive representation allows the six methods to achieve better results than end-to-end learning and represent a new reference compare to the recent state of art. Results are also remarkable stable versus the noise level.
From Weakly Supervised Learning to Biquality Learning, a brief introduction
Dec 16, 2020


The field of Weakly Supervised Learning (WSL) has recently seen a surge of popularity, with numerous papers addressing different types of "supervision deficiencies". In WSL use cases, a variety of situations exists where the collected "information" is imperfect. The paradigm of WSL attempts to list and cover these problems with associated solutions. In this paper, we review the research progress on WSL with the aim to make it as a brief introduction to this field. We present the three axis of WSL cube and an overview of most of all the elements of their facets. We propose three measurable quantities that acts as coordinates in the previously defined cube namely: Quality, Adaptability and Quantity of information. Thus we suggest that Biquality Learning framework can be defined as a plan of the WSL cube and propose to re-discover previously unrelated patches in WSL literature as a unified Biquality Learning literature.
Importance Reweighting for Biquality Learning
Oct 19, 2020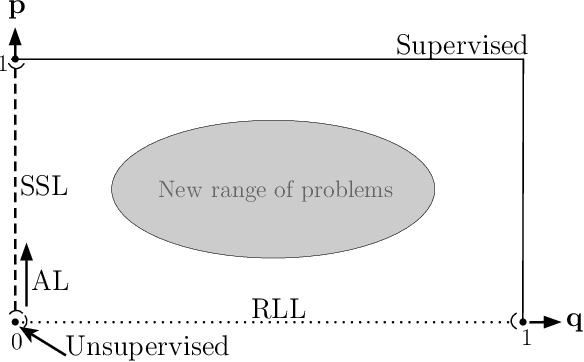

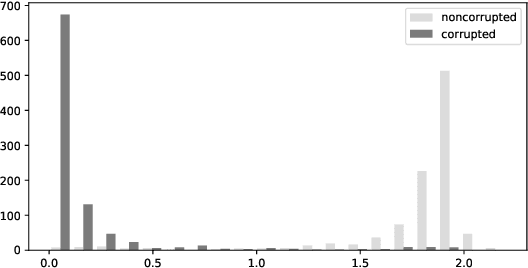
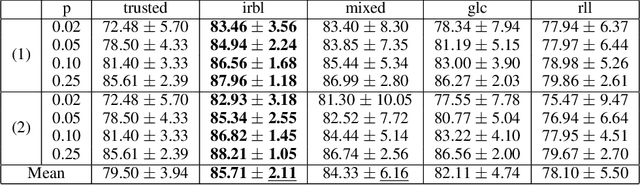
The field of Weakly Supervised Learning (WSL) has recently seen a surge of popularity, with numerous papers addressing different types of ``supervision deficiencies'', namely: poor quality, non adaptability, and insufficient quantity of labels. Regarding quality, label noise can be of different kinds, including completely-at-random, at-random or even not-at-random. All these kinds of label noise are addressed separately in the literature, leading to highly specialized approaches. This paper proposes an original view of Weakly Supervised Learning, to design generic approaches capable of dealing with any kind of label noise. For this purpose, an alternative setting called ``Biquality data'' is used. This setting assumes that a small trusted dataset of correctly labeled examples is available, in addition to the untrusted dataset of noisy examples. In this paper, we propose a new reweigthing scheme capable of identifying noncorrupted examples in the untrusted dataset. This allows one to learn classifiers using both datasets. Extensive experiments demonstrate that the proposed approach outperforms baselines and state-of-the-art approaches, by simulating several kinds of label noise and varying the quality and quantity of untrusted examples.